
{kind=link}
DeepSeek AI launched DeepSeek-OCR 2, an open supply doc OCR and understanding system that restructures its imaginative and prescient encoder to learn pages in a causal order that’s nearer to how people scan complicated paperwork. The important thing element is DeepEncoder V2, a language mannequin model transformer that converts a 2D web page right into a 1D sequence of visible tokens that already observe a realized studying stream earlier than textual content decoding begins.
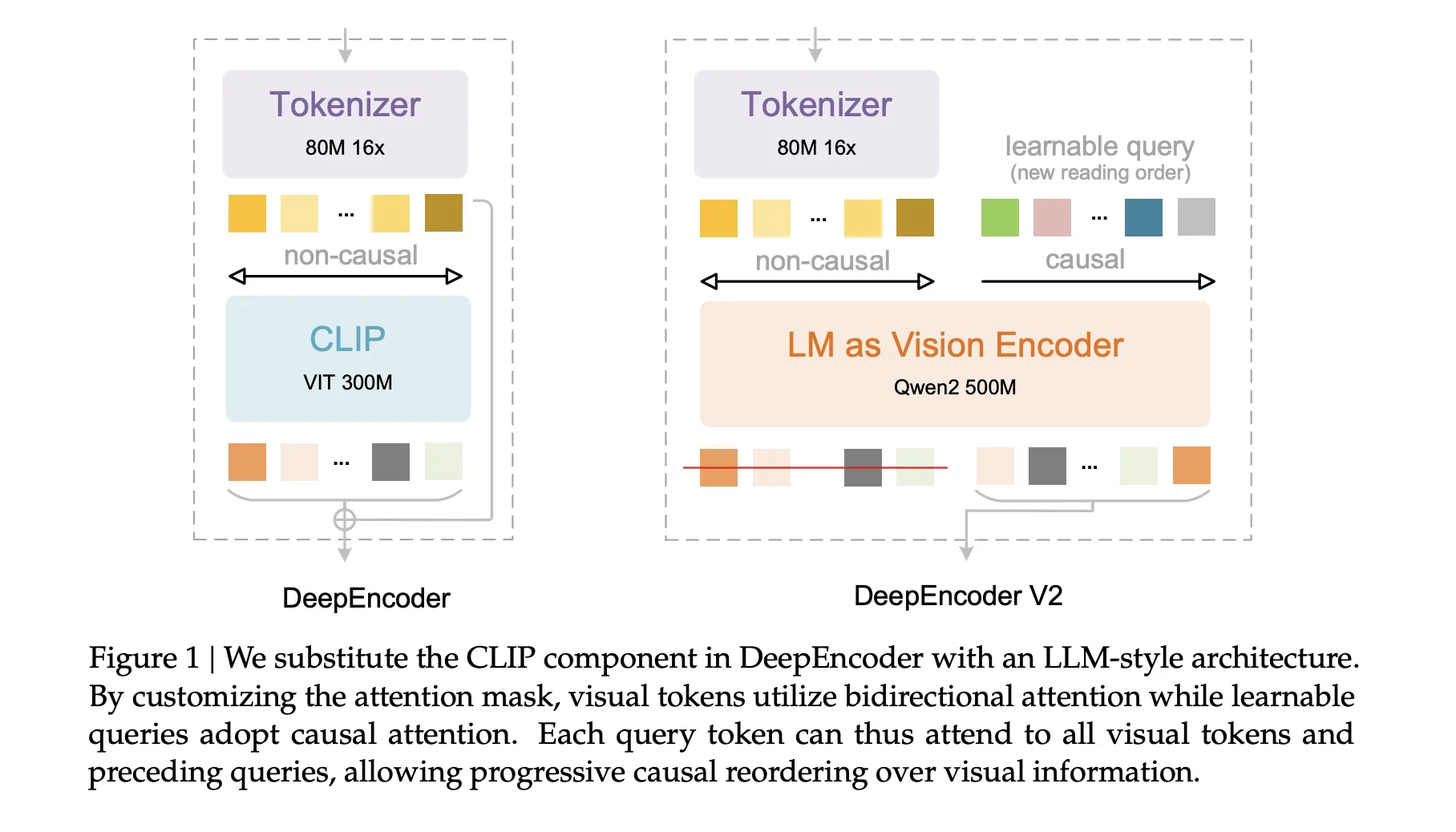
From raster order to causal visible stream
Most multimodal fashions nonetheless flatten photographs into a hard and fast raster sequence, high left to backside proper, and apply a transformer with static positional encodings. This can be a poor match for paperwork with multi column layouts, nested tables, and blended language areas. Human readers as a substitute observe a semantic order that jumps between areas.
DeepSeek-OCR 2 retains the encoder and decoder construction of DeepSeek-OCR, however replaces the unique CLIP ViT primarily based visible encoder with DeepEncoder V2. The decoder stays DeepSeek-3B-A500M, a MoE language mannequin with about 3B complete parameters and about 500M lively parameters per token. The aim is to let the encoder carry out causal reasoning over visible tokens and handy the decoder a sequence that’s already aligned with a possible studying order.
Imaginative and prescient tokenizer and token finances
The imaginative and prescient tokenizer is inherited from DeepSeek-OCR. It makes use of an 80M parameter SAM base spine adopted by 2 convolution layers. This stage downsamples the picture in order that the visible token depend is lowered by an element of 16 and compresses options into an embedding dimension of 896.
DeepSeek-OCR 2 makes use of a world and native multi crop technique to cowl dense pages with out letting the token depend explode. A world view at 1024 × 1024 decision produces 256 tokens. As much as 6 native crops at 768 × 768 decision add 144 tokens every. In consequence, the visible token depend ranges from 256 to 1120 per web page. This higher sure is barely smaller than the 1156 token finances used within the authentic DeepSeek-OCR’s Gundam mode, and it’s corresponding to the finances utilized by Gemini-3 Professional on OmniDocBench.
DeepEncoder-V2, language mannequin as imaginative and prescient encoder
DeepEncoder-V2 is constructed by instantiating a Qwen2-0.5B model transformer because the imaginative and prescient encoder. The enter sequence is constructed as follows. First, all visible tokens from the tokenizer type the prefix. Then a set of learnable question tokens, known as causal stream tokens, is appended because the suffix. The variety of causal stream tokens equals the variety of visible tokens.
The eye sample is uneven. Visible tokens use bidirectional consideration and see all different visible tokens. Causal stream tokens use causal consideration and may see all visible tokens and solely earlier causal stream tokens. Solely the outputs at causal stream positions are handed to the decoder. In impact, the encoder learns a mapping from a 2D grid of visible tokens right into a 1D causal sequence of stream tokens that encode a proposed studying order and native context.
This design decomposes the issue into 2 levels. DeepEncoder-V2 performs causal reasoning over visible construction and studying order. DeepSeek-3B-A500M then performs causal decoding over textual content conditioned on this reordered visible enter.

Coaching pipeline
The coaching knowledge pipeline follows DeepSeek-OCR and focuses on OCR intensive content material. OCR knowledge accounts for 80 p.c of the combination. The analysis staff rebalances the sampling throughout textual content, formulation, and tables utilizing a 3:1:1 ratio in order that the mannequin sees sufficient construction heavy examples.
Coaching runs in 3 levels:
In stage 1, encoder pretraining {couples} DeepEncoder-V2 to a small decoder and makes use of a typical language modeling goal. The mannequin is skilled at 768×768 and 1024×1024 resolutions with multi scale sampling. The imaginative and prescient tokenizer is initialized from the unique DeepEncoder. The LLM model encoder is initialized from Qwen2-0.5B base. The optimizer is AdamW with cosine studying charge decay from 1e-4 to 1e-6 over 40k iterations. Coaching makes use of about 160 A100 GPUs, sequence size 8k with packing, and a big combination of doc picture textual content samples.
In stage 2, question enhancement attaches DeepEncoder-V2 to DeepSeek-3B-A500M and introduces multi crop views. The tokenizer is frozen. The encoder and decoder are collectively skilled with 4 stage pipeline parallelism and 40 knowledge parallel replicas. The worldwide batch dimension is 1280 and the schedule runs for 15k iterations with studying charge decay from 5e-5 to 1e-6.
In stage 3, all encoder parameters are frozen. Solely the DeepSeek decoder is skilled to raised adapt to the reordered visible tokens. This stage makes use of the identical batch dimension however a shorter schedule and a decrease studying charge that decays from 1e-6 to 5e-8 over 20k iterations. Freezing the encoder greater than doubles coaching throughput at this stage.
Benchmark outcomes on OmniDocBench
The primary analysis makes use of OmniDocBench-v1.5. This benchmark incorporates 1355 pages in 9 doc classes in Chinese language and English, together with books, educational papers, varieties, shows, and newspapers. Every web page is annotated with format parts akin to textual content spans, equations, tables, and figures.
DeepSeek-OCR 2 achieves an total OmniDocBench rating of 91.09 with a visible token most of 1120. The unique DeepSeek-OCR baseline scores 87.36 with a token most of 1156. DeepSeek-OCR 2 subsequently positive aspects 3.73 factors whereas utilizing a barely smaller token finances.
Studying order (R-order) Edit Distance, which measures the distinction between predicted and floor reality studying sequences, drops from 0.085 to 0.057. Textual content edit distance falls from 0.073 to 0.048. Method and desk edit distances additionally lower, which signifies higher parsing of math and structured areas.
Considered as a doc parser, DeepSeek-OCR-2 achieves total aspect degree edit distance 0.100. The unique DeepSeek-OCR reaches 0.129 and Gemini-3 Professional reaches 0.115 below comparable visible token constraints. This means that the causal visible stream encoder improves structural constancy with out increasing the token finances.
Class sensible, DeepSeek-OCR-2 improves textual content edit distance for many doc sorts, akin to educational papers and books. Efficiency is weaker on very dense newspapers, the place textual content edit distance stays above 0.13. The analysis staff hyperlink this to restricted coaching knowledge for newspapers and heavy compression on excessive textual content density. Studying order metrics, nevertheless, enhance throughout all classes.

Key Takeaways
- DeepSeek-OCR 2 replaces a CLIP ViT model encoder with DeepEncoder-V2, a Qwen2-0.5B primarily based language mannequin encoder that converts a 2D doc web page right into a 1D sequence of causal stream tokens aligned with a realized studying order.
- The imaginative and prescient tokenizer makes use of an 80M parameter SAM base spine with convolutions, multi crop world and native views, and retains the visible token finances between 256 and 1120 tokens per web page, barely beneath the unique DeepSeek-OCR Gundam mode whereas remaining corresponding to Gemini 3 Professional.
- Coaching follows a 3 stage pipeline, encoder pretraining, joint question enhancement with DeepSeek-3B-A500M, and decoder solely fine-tuning with the encoder frozen, utilizing an OCR heavy knowledge combine with 80 p.c OCR knowledge and a 3 to 1 to 1 sampling ratio over textual content, formulation, and tables.
- On OmniDocBench v1.5 with 1355 pages and 9 doc classes, DeepSeek-OCR 2 reaches an total rating of 91.09 versus 87.36 for DeepSeek-OCR, reduces studying order edit distance from 0.085 to 0.057, and achieves aspect degree edit distance 0.100 in contrast with 0.129 for DeepSeek-OCR and 0.115 for Gemini-3 Professional below comparable visible token budgets.
Take a look at the Paper, Repo and Model weights. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.