
{kind=link}
So a pair days in the past I used to be having a chat with a good friend about how Meshtastic works. He casually requested, “Effectively, why cannot you ship audio?” I defined that bandwidth merely is not sufficient because it operates on low-energy sub-GHz frequencies. These frequencies give us wonderful vary however include critical information limitations – we’re speaking kilobytes per minute, not the megabytes per second we’re used to with fashionable communications.
Quick ahead a bit, and I observed one thing fascinating within the Meshtastic docs – a mode preset for LoRa known as SHORT_TURBO (described as “Quickest, highest bandwidth, lowest airtime, shortest vary. It isn’t authorized to make use of in all areas because of its 500kHz bandwidth.”).
This obtained me questioning: if we will ship textual content tremendous quick (although “quick” in LoRa phrases remains to be not that quick), why cannot we ship audio or voice notes?
Earlier Discussions with Devs
We had a speak about audio transmission a couple of yr in the past with the Meshtastic builders, and understandably, they weren’t followers of the concept. Think about holding the frequency for 30-60 seconds simply to ship a voice message – it will deliver the entire community down and make it unreliable, particularly contemplating how the Meshtastic neighborhood is rising. That might actually harm efficiency for a lot of customers.
The devs identified that LoRa was designed for small, rare information packets – not streaming media. A typical Meshtastic configuration would possibly solely enable for 5-20 bytes per second relying on settings and circumstances. Evaluate that to the roughly 8 kilobytes per second wanted for even essentially the most compressed voice audio, and you’ll see the issue.
However on the similar time, I actually needed to check it. I simply needed to see if we might truly do it. Possibly somebody would consider a pleasant option to optimize it for manufacturing ultimately.
Earlier than we proceed, let’s give a shoutout to our sponsor for this weblog: Telemetry Harbor.
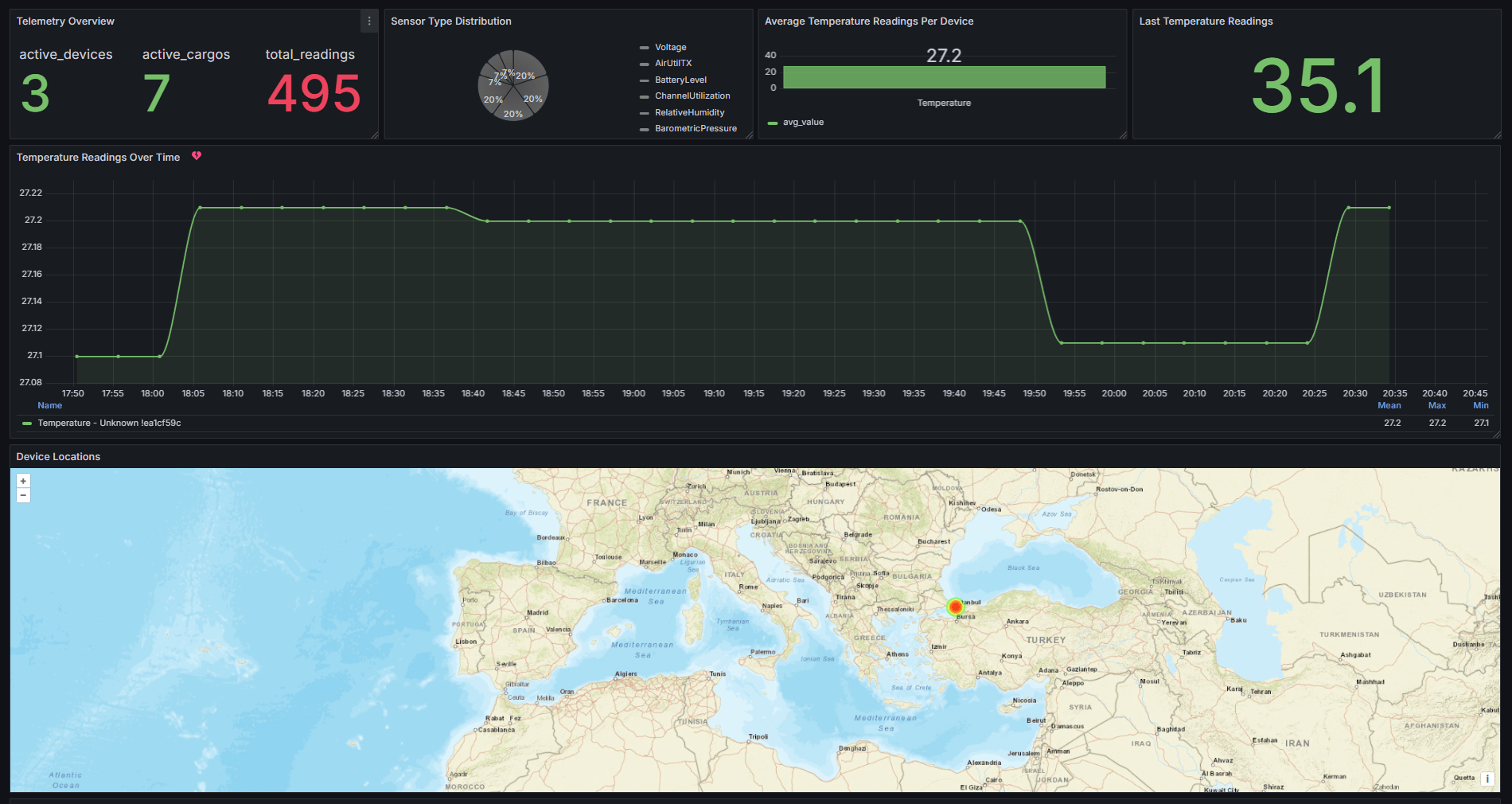
Telemetry Harbor is an all-in-one answer to Gather, Retailer & Visualize Your IoT Knowledge — All in One Place. It is very easy – create an account, after which it is only a matter of some HTTPS requests to see your information in Grafana. Tremendous easy, tremendous quick time to first information level.
Together with Harbor AI to speak to your information, it is like having a private assistant that is aware of every little thing about your metrics. They’ve plenty of integrations, together with a Meshtastic integration the place you may monitor your community and node telemetry.
How to Visualize Meshtastic Telemetry on Grafana
Integrate Meshtastic with Grafana for real-time monitoring and customizable dashboards. Visualize device data, including location, and interact with your data using Harbor AI. Effortlessly manage and analyze your telemetry with Telemetry Harbor
The Preliminary Plan
With this problem in thoughts, I began serious about approaches. I clearly did not wish to construct my very own firmware and app from scratch – that may positively develop past a weekend mission.
So my concept was: if we will ship messages, what if we convert audio to textual content, ship the textual content, then convert it again to audio? On paper, it appeared doable.
Being the vibe coder I’m, I fired up my $20 LLM subscription and set to work. I requested for Python code to work together with the Meshtastic library to file a voice notice, convert it to textual content, and ship it, with plans for the receiving node to transform it again to audio.
Meshtastic Library Limitations
Instantly after implementing the answer, I obtained an error: the message is greater than 256 bytes. This was anticipated – it is a limitation clearly proven by the iOS app and in every single place else that you may’t ship lengthy messages.
The error got here from the Python library’s validation checks:
if len(encoded_message) > 256:
increase Exception(f"Message exceeds most measurement of 256 bytes (was {len(encoded_message)} bytes)")I believed, “OK, perhaps if I can overcome the library limitation, perhaps the gadget will ship it.” So I dug by the library code and eliminated the validation examine. I recorded a voice pattern, despatched it, and the logs mentioned “despatched efficiently.” However wait – nothing was acquired on the opposite aspect. Evidently the gadget firmware additionally has a examine in place.
Customized Firmware Try
After a bit extra digging, I discovered that the firmware has a Protocol Buffer fixed that defines the message size. The protobuf definition within the firmware restricted the message measurement:
/*
* From mesh.choices
* notice: this payload size is ONLY the bytes which can be despatched within the Knowledge protobuf (excluding protobuf overhead). The 16 byte header is
* exterior of this envelope
*/
DATA_PAYLOAD_LEN = 233;So I did what any logical individual would do – cloned the repo, edited the DATA_PAYLOAD_LEN worth to 150000, recompiled the firmware, flashed two units, and tried to ship one other message.
What occurred? Nothing – similar consequence. The logs confirmed “message despatched efficiently,” however nothing appeared on the receiving aspect. After extra investigation, I discovered that there are a number of layers of validation all through the stack.
Useless Easy
So I gave up on making an attempt to beat Meshtastic’s elementary limits. First, I did not have a lot time, and likewise it will be exhausting to doc this course of in a weblog and inform individuals to check it themselves.
I believed, “OK, let’s convert the voice notice to textual content, chunk it so it does not exceed the restrict, and ship it in components with some metadata so we will reassemble it on the opposite aspect.” With assist from my $20 LLM, I arrange some predefined chunk sizes and compression ranges.
The technical implementation regarded one thing like this:
- Report audio utilizing PyAudio at 8kHz, mono, 16-bit PCM
- Compress the audio utilizing totally different compression algorithms:
- “Very Low” high quality: Excessive MP3 compression at 8kbps
- “Low” high quality: MP3 compression at 16kbps
- “Medium” high quality: MP3 compression at 32kbps
- “Excessive” high quality: MP3 compression at 64kbps
- Break up the compressed information into chunks with metadata headers:
- Small chunks: 150 bytes of payload information per message
- Medium chunks: 200 bytes of payload information per message
- Giant chunks: 230 bytes of payload information per message
- Ship every chunk as a separate message
- On the receiving finish, gather chunks and reassemble when all are acquired
- Decompress and play again the audio
Add sequence headers to every chunk:
VOICE|[total_chunks]|[chunk_number]|[compression_level]|[payload]Testing the Chunking Method
I recorded a voice notice with the utmost compression (“Very Low” high quality) and medium chunk measurement. The system began sending “1/27 chunks” and saved going. And what have you learnt? On the opposite aspect, I began receiving chunks! After an extended whereas, the voice notice indicator popped up on the receiver.
Once I tried to play it, although, it blew my ears out – plenty of noise. The compression was too aggressive, inflicting vital audio artifacts. So I stepped down the compression a bit to “Low” high quality and tried one other recording. This time it was one thing like 200 chunks, so it took a great minute or two to transmit. However then it appeared on the opposite aspect, and once I clicked play… the voice performed clearly! It labored! I might truly ship audio by Meshtastic.
The technical breakdown of what labored greatest:
- “Very Low” compression high quality (8kbps MP3)
- “Small” chunks (150 bytes)
- 1-2 second voice messages resulted in about 50-60 chunks
- Complete transmission time: roughly 30-120 seconds
The Potential
This experiment made me take into consideration catastrophe conditions the place you would possibly want extra than simply textual content. Technically, you would ship not simply voice however something, as evident from different tasks just like the Reticulum community the place you may ship recordsdata, photos, and so on.
Now, this is not well-supported by the iOS app, however hey, it is attainable! It’d saturate the community, however the backside line is: we will do it. We simply should discover a intelligent method of doing it whereas preserving the Meshtastic community truthful for everybody.
Limitations
The code will not be by any means steady. Generally with massive chunk numbers like 400, it will begin sending however halfway by, the receiving node would cease getting chunks. I attempted ready for acknowledgments, however that may take ages to ship something.
Listed below are the important thing technical limitations I encountered:
- Reliability Points: With no strong acknowledgment system, chunks typically obtained misplaced
- Community Congestion: Sending a number of chunks in fast succession would flood the community
- Time Constraints: A ten-second audio clip might take 1-2 minutes to transmit
- Battery Affect: Steady transmission dramatically diminished gadget battery life
- Audio High quality: Even at “Low” high quality, audio was noticeably compressed
- Vary Discount: In “SHORT_TURBO” mode, vary was considerably diminished
Possibly one thing like what’s utilized in FTP or HTTPS may very well be carried out to proceed the obtain the place it left off. Once more, I am pushing the boundaries of what Meshtastic is designed for.
However – and this can be a massive BUT – perhaps if the message restrict was increased, we might ship audio quicker since it will be one steady transmission relatively than chunks with overhead, acknowledgments, and so on.
One other factor to think about is that audio information is fairly massive for LoRa. So neglect about something greater than 5-10 seconds of first rate high quality. Would that even be price it? You will get extra bandwidth with decrease vary, however then why not simply use UHF or VHF radio?
Need to Strive It Your self?
If you happen to’re adventurous and wish to experiment with voice messaging over Meshtastic, I’ve made the proof-of-concept utility out there on GitHub:
GitHub – TelemetryHarbor/meshtastic-voice-messenger: Meshtastic Voice Messenger is an experimental Python application that explores the possibility of transmitting compressed audio data over Meshtastic mesh networks.
Meshtastic Voice Messenger is an experimental Python application that explores the possibility of transmitting compressed audio data over Meshtastic mesh networks. – TelemetryHarbor/meshtastic-voic…
Necessary: That is strictly a proof of idea and never supposed for manufacturing use. The transmission is unreliable and serves primarily to display the chance.
Options of the Meshtastic Voice Messenger:
- Report voice messages of configurable size
- Compress audio utilizing totally different high quality settings
- Break up massive messages into chunks for transmission
- Reassemble acquired chunks into full audio messages
- Play acquired voice messages
- Ship take a look at messages to confirm connectivity
- Detailed logging for debugging
Necessities:
- Python 3.7+
- Meshtastic-compatible gadget (e.g., T-Beam, Heltec, LilyGo)
- Required Python packages: meshtastic, pyaudio, numpy, tkinter
Fast Setup:
- Clone the repository:
git clone https://github.com/TelemetryHarbor/meshtastic-voice-messenger.git
cd meshtastic-voice-messenger- Set up required packages:
pip set up meshtastic pyaudio numpy- Join your Meshtastic gadget by way of USB
- Run the appliance:
python app.pyBear in mind: Each the sender and receiver have to run the appliance for the voice messaging to work. Additionally, remember the fact that by in depth testing, I discovered that “Very Low” compression high quality and “Small” chunk measurement (150 bytes) present one of the best stability between audio high quality and transmission reliability.
Conclusion
I used to be simply curious and had a free weekend, so I needed to strive one thing cool. This may very well be the beginning for some plugins or new instruments for Meshtastic. The potential is there, even when the sensible utility may be restricted.
Whereas this proof of idea demonstrates that voice transmission is technically attainable, a production-ready implementation would require:
- Extra environment friendly compression algorithms
- Higher error correction and restoration mechanisms
- Improved acknowledgment and retry logic
- Optimized bandwidth utilization
- Integration with the Meshtastic protocol at a deeper stage
Who is aware of what different capabilities we’d uncover as we maintain pushing the boundaries of this fascinating expertise? If you happen to’re serious about contributing to this experiment or have concepts for enchancment, be at liberty to fork the repository and submit pull requests!