
{kind=link}
Multimodal Attributed Graphs (MMAGs) have acquired little consideration regardless of their versatility in picture era. MMAGs characterize relationships between entities with combinatorial complexity in a graph-structured method. Nodes within the graph comprise each picture and textual content data. In comparison with textual content or picture conditioning fashions, graphs could possibly be transformed into higher and extra informative photos. Graph2Image is an fascinating problem on this area that requires generative fashions to synthesize picture conditioning on textual content descriptions and graph connections. Whereas MMAGs are useful, they can’t be immediately integrated into picture and textual content conditioning.
The next are essentially the most related challenges in the usage of MMAGs for picture synthesis:
- Explosion in graph measurement– This phenomenon happens because of the combinatorial complexity of graphs, the place the dimensions grows exponentially as we introduce to the mannequin native subgraphs, which embody photos and textual content.
- Graph entities dependencies – Nodal traits are mutually dependent, and thus, their proximity displays the relationships between entities throughout textual content and picture and their choice in picture era. To exemplify this, producing a light-colored shirt ought to have a choice for mild shades resembling pastels.
- Want for controllability in graph situation – The interpretability of generated photos should be managed to observe desired patterns or traits outlined by connections between entities within the graph.
A staff of researchers on the College of Illinois developed InstructG2I to unravel this downside. This can be a graph context-aware diffusion mannequin that makes use of multimodal graph data. This strategy addresses graph area complexity by compressing contexts from graphs into fastened capability graph conditioning tokens enhanced with semantic personalised PageRank-based graph sampling. The Graph-QFormer structure additional improves these graph tokens by fixing the issue of graph entity dependency. Final however not least, InstructG2I guides picture era with adjustable edge lengths.
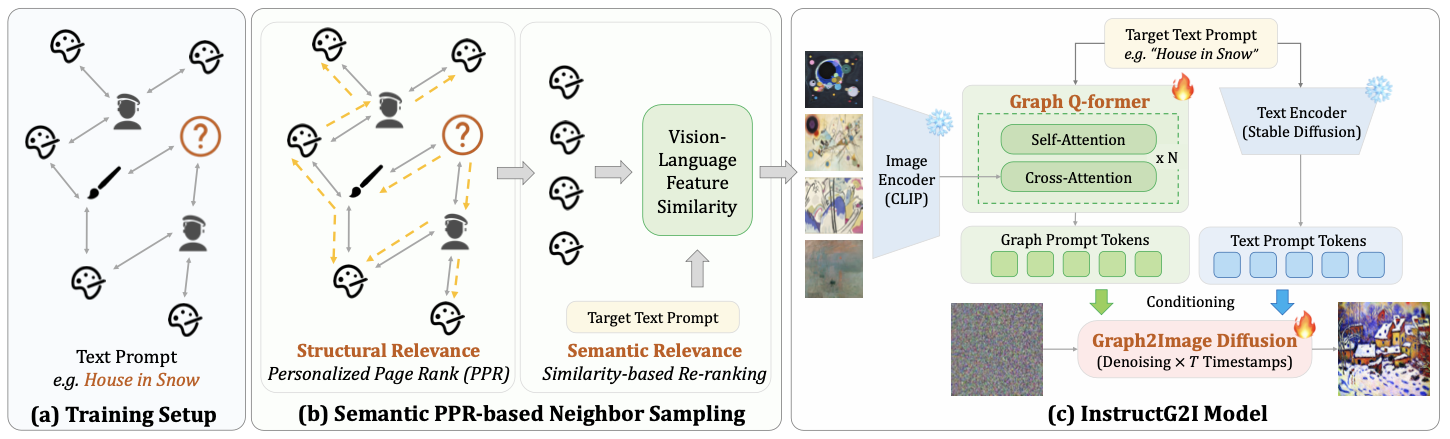
InstructG2I introduces Graph Situations into Secure Diffusion with PPR-based neighbor sampling. PPR or Personalised PageRank identifies associated nodes from the graph construction. To make sure that generated photos are semantically associated to the goal node a semantic based mostly similarity calculation operate is used for reranking.This research additionally proposes Graph-QFormer which is a two transformer module to seize textual content based mostly and picture based mostly dependencies. Graph-QFormer employs multi head self consideration for image-image dependencies and multi head cross consideration for text-image dependencies.Cross Consideration layer aligns picture options with textual content prompts. It makes use of hidden states from the self-attention layer as enter, and the textual content embeddings as a question to generate related photos. Last output from the 2 transformers of Graph-QFormer is the graph-conditioned immediate tokens which information the picture era course of within the diffusion mannequin.Lastly to manage the era course of classifier-free steerage is used which is mainly a method to regulate the power of graphs
InstructG2I was examined on three datasets from totally different domains – ART500K, Amazon, and Goodreads. For text-to-image strategies, Secure Diffusion 1.5 was determined because the baseline mannequin, and for image-to-image strategies, InstructPix2Pix and ControlNet had been chosen for comparability; each had been initialized with SD 1.5 and fine-tuned on chosen datasets. The research’s outcomes confirmed spectacular enhancements over baseline fashions in each duties. InstructG2I outperformed all baseline fashions in CLIP and DINOv2 scores. For qualitative analysis, InstructG2I generated photos that greatest match the semantics of the textual content immediate and context from the graph, guaranteeing the era of content material and context because it realized from the neighbors on the graph and precisely conveyed data.
InstructG2I successfully solved the numerous challenges of the explosion, inter-entity dependency, and controllability in Multimodal Attributed Graphs and outdated the baseline in picture era. Within the subsequent few years, there might be a number of alternatives to work with and incorporate Graphs into picture era, a giant a part of which incorporates dealing with the complicated heterogeneous relationships between picture and textual content on MMAGs.
Take a look at the Paper, Code, and Details. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our newsletter.. Don’t Overlook to hitch our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Adeeba Alam Ansari is presently pursuing her Twin Diploma on the Indian Institute of Expertise (IIT) Kharagpur, incomes a B.tech in Industrial Engineering and an M.tech in Monetary Engineering. With a eager curiosity in machine studying and synthetic intelligence, she is an avid reader and an inquisitive particular person. Adeeba firmly believes within the energy of expertise to empower society and promote welfare by way of progressive options pushed by empathy and a deep understanding of real-world challenges.