
{kind=link}
NVIDIA Researchers launched PersonaPlex-7B-v1, a full duplex speech to speech conversational mannequin that targets pure voice interactions with exact persona management.
From ASR→LLM→TTS to a single full duplex mannequin
Typical voice assistants often run a cascade. Automated Speech Recognition (ASR) converts speech to textual content, a language mannequin generates a textual content reply, and Textual content to Speech (TTS) converts again to audio. Every stage provides latency, and the pipeline can’t deal with overlapping speech, pure interruptions, or dense backchannels.
PersonaPlex replaces this stack with a single Transformer mannequin that performs streaming speech understanding and speech technology in a single community. The mannequin operates on steady audio encoded with a neural codec and predicts each textual content tokens and audio tokens autoregressively. Incoming consumer audio is incrementally encoded, whereas PersonaPlex concurrently generates its personal speech, which allows barge in, overlaps, speedy flip taking, and contextual backchannels.
PersonaPlex runs in a twin stream configuration. One stream tracks consumer audio, the opposite stream tracks agent speech and textual content. Each streams share the identical mannequin state, so the agent can maintain listening whereas talking and might alter its response when the consumer interrupts. This design is straight impressed by Kyutai’s Moshi full duplex framework.
Hybrid prompting, voice management and function management
PersonaPlex makes use of two prompts to outline the conversational id.
- The voice immediate is a sequence of audio tokens that encodes vocal traits, talking type, and prosody.
- The textual content immediate describes function, background, group data, and state of affairs context.
Collectively, these prompts constrain each the linguistic content material and the acoustic habits of the agent. On high of this, a system immediate helps fields akin to identify, enterprise identify, agent identify, and enterprise data, with a price range as much as 200 tokens.
Structure, Helium spine and audio path
The PersonaPlex mannequin has 7B parameters and follows the Moshi community structure. A Mimi speech encoder that mixes ConvNet and Transformer layers converts waveform audio into discrete tokens. Temporal and depth Transformers course of a number of channels that signify consumer audio, agent textual content, and agent audio. A Mimi speech decoder that additionally combines Transformer and ConvNet layers generates the output audio tokens. Audio makes use of a 24 kHz pattern charge for each enter and output.
PersonaPlex is constructed on Moshi weights and makes use of Helium because the underlying language mannequin spine. Helium gives semantic understanding and allows generalization exterior the supervised conversational situations. That is seen within the ‘house emergency’ instance, the place a immediate a couple of reactor core failure on a Mars mission results in coherent technical reasoning with acceptable emotional tone, regardless that this case shouldn’t be a part of the coaching distribution.
Coaching information mix, actual conversations and artificial roles
Coaching has 1 stage and makes use of a mix of actual and artificial dialogues.
Actual conversations come from 7,303 calls, about 1,217 hours, within the Fisher English corpus. These conversations are again annotated with prompts utilizing GPT-OSS-120B. The prompts are written at completely different granularity ranges, from easy persona hints like ‘You get pleasure from having dialog’ to longer descriptions that embrace life historical past, location, and preferences. This corpus gives pure backchannels, disfluencies, pauses, and emotional patterns which can be troublesome to acquire from TTS alone.
Artificial information covers assistant and customer support roles. NVIDIA workforce studies 39,322 artificial assistant conversations, about 410 hours, and 105,410 artificial customer support conversations, about 1,840 hours. Qwen3-32B and GPT-OSS-120B generate the transcripts, and Chatterbox TTS converts them to speech. For assistant interactions, the textual content immediate is fastened as ‘You’re a smart and pleasant trainer. Reply questions or present recommendation in a transparent and interesting manner.’ For customer support situations, prompts encode group, function kind, agent identify, and structured enterprise guidelines akin to pricing, hours, and constraints.
This design lets PersonaPlex disentangle pure conversational habits, which comes primarily from Fisher, from job adherence and function conditioning, which come primarily from artificial situations.
Analysis on FullDuplexBench and ServiceDuplexBench
PersonaPlex is evaluated on FullDuplexBench, a benchmark for full duplex spoken dialogue fashions, and on a brand new extension known as ServiceDuplexBench for customer support situations.
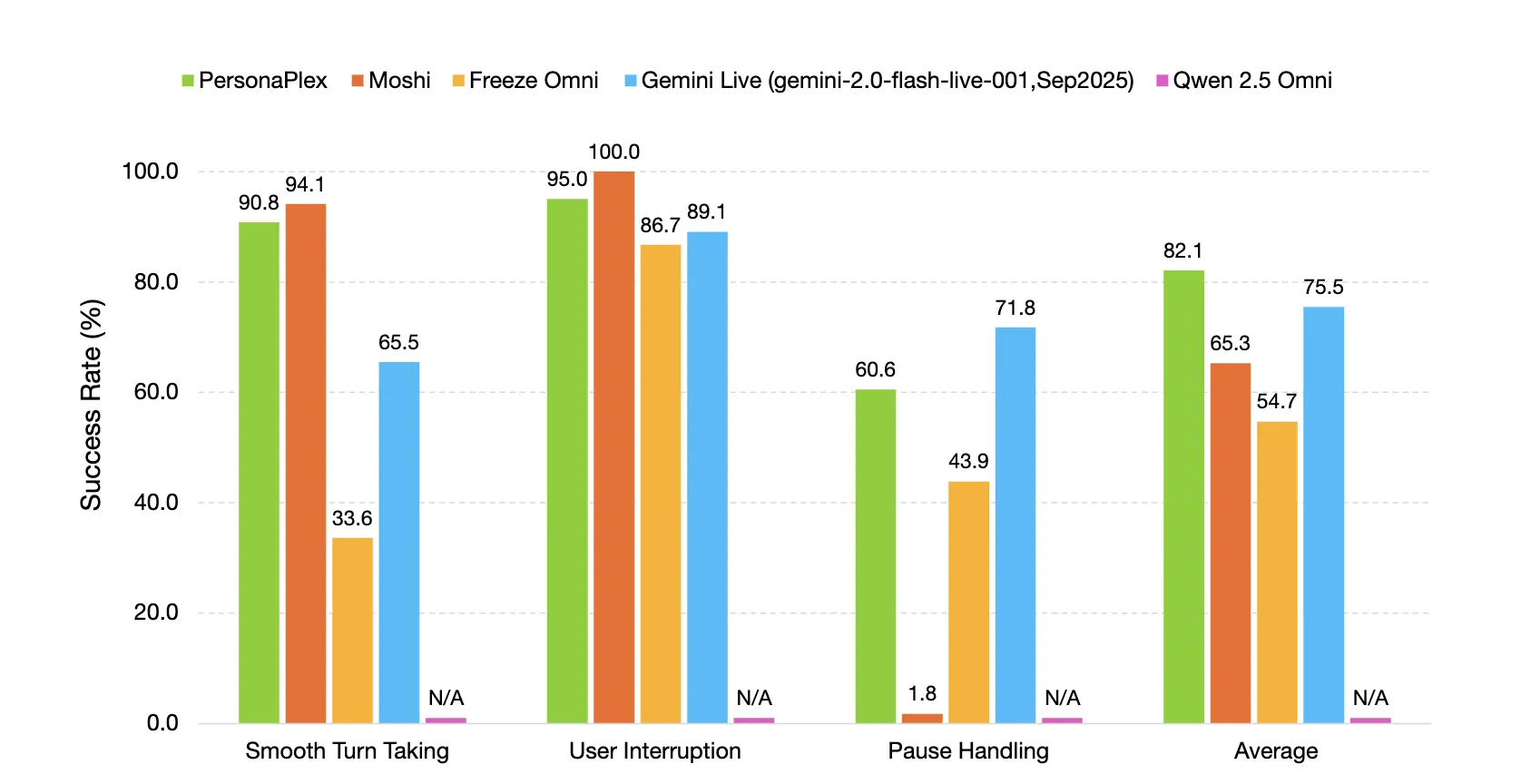
FullDuplexBench measures conversational dynamics with Takeover Price and latency metrics for duties akin to clean flip taking, consumer interruption dealing with, pause dealing with, and backchanneling. GPT-4o serves as an LLM decide for response high quality in query answering classes. PersonaPlex reaches clean flip taking TOR 0.908 with latency 0.170 seconds and consumer interruption TOR 0.950 with latency 0.240 seconds. Speaker similarity between voice prompts and outputs on the consumer interruption subset makes use of WavLM TDNN embeddings and reaches 0.650.
PersonaPlex outperforms many different open supply and closed methods on conversational dynamics, response latency, interruption latency, and job adherence in each assistant and customer support roles.
Key Takeaways
- PersonaPlex-7B-v1 is a 7B parameter full duplex speech to speech conversational mannequin from NVIDIA, constructed on the Moshi structure with a Helium language mannequin spine, code underneath MIT and weights underneath the NVIDIA Open Mannequin License.
- The mannequin makes use of a twin stream Transformer with Mimi speech encoder and decoder at 24 kHz, it encodes steady audio into discrete tokens and generates textual content and audio tokens on the similar time, which allows barge in, overlaps, quick flip taking, and pure backchannels.
- Persona management is dealt with by hybrid prompting, a voice immediate manufactured from audio tokens units timbre and elegance, a textual content immediate and a system immediate of as much as 200 tokens defines function, enterprise context, and constraints, with prepared made voice embeddings akin to NATF and NATM households.
- Coaching makes use of a mix of seven,303 Fisher conversations, about 1,217 hours, annotated with GPT-OSS-120B, plus artificial assistant and customer support dialogs, about 410 hours and 1,840 hours, generated with Qwen3-32B and GPT-OSS-120B and rendered with Chatterbox TTS, which separates conversational naturalness from job adherence.
- On FullDuplexBench and ServiceDuplexBench, PersonaPlex reaches clean flip taking takeover charge 0.908 and consumer interruption takeover charge 0.950 with sub second latency and improved job adherence.
Take a look at the Technical details, Model weights and Repo. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.