
{kind=link}
Preparing article title...
[ad_1]
Smaller Fashions with Smarter Efficiency and 256K Context Assist
Alibaba’s Qwen group has launched two highly effective additions to its small language mannequin lineup: Qwen3-4B-Instruct-2507 and Qwen3-4B-Pondering-2507. Regardless of having solely 4 billion parameters, these fashions ship distinctive capabilities throughout general-purpose and expert-level duties whereas working effectively on consumer-grade {hardware}. Each are designed with native 256K token context home windows, which means they’ll course of extraordinarily lengthy inputs resembling massive codebases, multi-document archives, and prolonged dialogues with out exterior modifications.
Structure and Core design
Each fashions characteristic 4 billion complete parameters (3.6B excluding embeddings) constructed throughout 36 transformer layers. They use Grouped Question Consideration (GQA) with 32 question heads and 8 key/worth heads, enhancing effectivity and reminiscence administration for very massive contexts. They’re dense transformer architectures—not mixture-of-experts—which ensures constant activity efficiency. Lengthy-context help as much as 262,144 tokens is baked immediately into the mannequin structure, and every mannequin is pretrained extensively earlier than present process alignment and security post-training to make sure accountable, high-quality outputs.
Qwen3-4B-Instruct-2507 — A Multilingual, Instruction-Following Generalist
The Qwen3-4B-Instruct-2507 mannequin is optimized for velocity, readability, and user-aligned instruction following. It’s designed to ship direct solutions with out specific step-by-step reasoning, making it excellent for situations the place customers need concise responses fairly than detailed thought processes.
Multilingual protection spans over 100 languages, making it extremely appropriate for international deployments in chatbots, buyer help, training, and cross-language search. Its native 256K context help permits it to deal with duties like analyzing massive authorized paperwork, processing multi-hour transcripts, or summarizing huge datasets with out splitting the content material.
Efficiency Benchmarks:
| Benchmark Process | Rating |
|---|---|
| Common Data (MMLU-Professional) | 69.6 |
| Reasoning (AIME25) | 47.4 |
| SuperGPQA (QA) | 42.8 |
| Coding (LiveCodeBench) | 35.1 |
| creative Writing | 83.5 |
| Multilingual Comprehension (MultiIF) | 69.0 |
In apply, this implies Qwen3-4B-Instruct-2507 can deal with every part from language tutoring in a number of languages to producing wealthy narrative content material, whereas nonetheless offering competent efficiency in reasoning, coding, and domain-specific information.
Qwen3-4B-Pondering-2507 — Skilled-Degree Chain-of-Thought Reasoning
The place the Instruct mannequin focuses on concise responsiveness, the Qwen3-4B-Pondering-2507 mannequin is engineered for deep reasoning and problem-solving. It mechanically generates specific chains of thought in its outputs, making its decision-making course of clear—particularly helpful for complicated domains like arithmetic, science, and programming.
This mannequin excels at technical diagnostics, scientific information interpretation, and multi-step logical evaluation. It’s suited to superior AI brokers, analysis assistants, and coding companions that must motive by way of issues earlier than answering.
Efficiency Benchmarks:
| Benchmark Process | Rating |
|---|---|
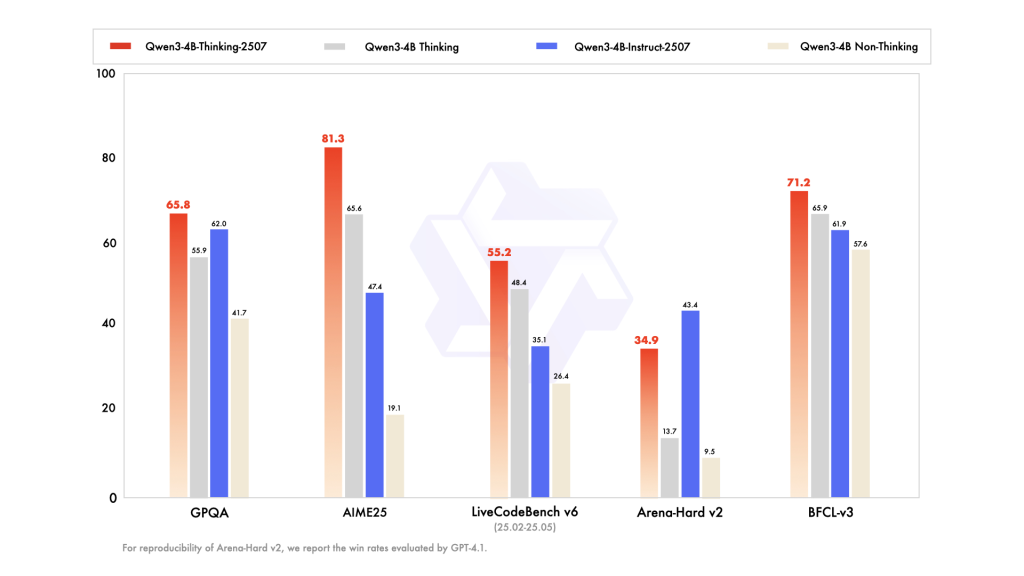
| Math (AIME25) | 81.3% |
| Science (HMMT25) | 55.5% |
| Common QA (GPQA) | 65.8% |
| Coding (LiveCodeBench) | 55.2% |
| Device Utilization (BFCL) | 71.2% |
| Human Alignment | 87.4% |
These scores reveal that Qwen3-4B-Pondering-2507 can match and even surpass a lot bigger fashions in reasoning-heavy benchmarks, permitting extra correct and explainable outcomes for mission-critical use instances.
Throughout Each Fashions
Each the Instruct and Pondering variants share key developments. The 256K native context window permits for seamless work on extraordinarily lengthy inputs with out exterior reminiscence hacks. Additionally they characteristic improved alignment, producing extra pure, coherent, and context-aware responses in creative and multi-turn conversations. Moreover, each are agent-ready, supporting API calling, multi-step reasoning, and workflow orchestration out-of-the-box.
From a deployment perspective, they’re extremely environment friendly—able to working on mainstream shopper GPUs with quantization for decrease reminiscence utilization, and absolutely appropriate with fashionable inference frameworks. This implies builders can run them regionally or scale them in cloud environments with out important useful resource funding.
Sensible Deployment and Purposes
Deployment is easy, with broad framework compatibility enabling integration into any fashionable ML pipeline. They can be utilized in edge units, enterprise digital assistants, analysis establishments, coding environments, and creative studios. Instance situations embody:
- Instruction-Following Mode: Buyer help bots, multilingual instructional assistants, real-time content material technology.
- Pondering Mode: Scientific analysis evaluation, authorized reasoning, superior coding instruments, and agentic automation.
Conclusion
The Qwen3-4B-Instruct-2507 and Qwen3-4B-Pondering-2507 show that small language models can rival and even outperform bigger fashions in particular domains when engineered thoughtfully. Their mix of long-context dealing with, sturdy multilingual capabilities, deep reasoning (in Pondering mode), and alignment enhancements makes them highly effective instruments for each on a regular basis and specialist AI functions. With these releases, Alibaba has set a brand new benchmark in making 256K-ready, high-performance AI fashions accessible to builders worldwide.
Try the Qwen3-4B-Instruct-2507 Model and Qwen3-4B-Thinking-2507 Model. Be happy to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to Subscribe to our Newsletter.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling complicated datasets into actionable insights.
[ad_2]
Source link