
On the AWS Summit in New York City, we launched a comprehensive suite of model customization capabilities for Amazon Nova basis fashions. Obtainable as ready-to-use recipes on Amazon SageMaker AI, you should utilize them to adapt Nova Micro, Nova Lite, and Nova Professional throughout the mannequin coaching lifecycle, together with pre-training, supervised fine-tuning, and alignment.
On this multi-post collection, we are going to discover these customization recipes and supply a step-by-step implementation information. We’re beginning with Direct Desire Optimization (DPO, an alignment method that provides a simple approach to tune mannequin outputs along with your preferences. DPO makes use of prompts paired with two responses—one most popular over the opposite—to information the mannequin towards outputs that higher replicate your required tone, type, or pointers. You may implement this method utilizing both parameter-efficient or full mannequin DPO, based mostly in your information quantity and price concerns. The personalized fashions may be deployed to Amazon Bedrock for inference utilizing provisioned throughput. The parameter-efficient model helps on-demand inference. Nova customization recipes can be found in SageMaker training jobs and SageMaker HyperPod, providing you with flexibility to pick the setting that most closely fits your infrastructure and scale necessities.
On this put up, we current a streamlined strategy to customizing Amazon Nova Micro with SageMaker coaching jobs.
Resolution overview
The workflow for utilizing Amazon Nova recipes with SageMaker coaching jobs, as illustrated within the accompanying diagram, consists of the next steps:
- The consumer selects a selected Nova customization recipe which gives complete configurations to manage Amazon Nova coaching parameters, mannequin settings, and distributed coaching methods. You should use the default configurations optimized for the SageMaker AI setting or customise them to experiment with completely different settings.
- The consumer submits an API request to the SageMaker AI management airplane, passing the Amazon Nova recipe configuration.
- SageMaker makes use of the coaching job launcher script to run the Nova recipe on a managed compute cluster.
- Based mostly on the chosen recipe, SageMaker AI provisions the required infrastructure, orchestrates distributed coaching, and, upon completion, robotically decommissions the cluster.
This streamlined structure delivers a totally managed consumer expertise, so you’ll be able to rapidly outline Amazon Nova coaching parameters and choose your most popular infrastructure utilizing easy recipes, whereas SageMaker AI handles the end-to-end infrastructure administration—inside a pay-as-you-go pricing mannequin that’s solely billed for the web coaching time in seconds.

The personalized Amazon Nova mannequin is subsequently deployed on Amazon Bedrock utilizing the createcustommodel API inside Bedrock – and might combine with native tooling equivalent to Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and Amazon Bedrock Agents.
Enterprise Use Case – Implementation Stroll-through
On this put up, we deal with adapting the Amazon Nova Micro mannequin to optimize structured perform calling for application-specific agentic workflows. We exhibit how this strategy can optimize Amazon Nova fashions for domain-specific use circumstances by a 81% improve in F1 rating and as much as 42% positive factors in ROUGE metrics. These enhancements make the fashions extra environment friendly in addressing a wide selection of enterprise functions, equivalent to enabling buyer assist AI assistants to intelligently escalate queries, powering digital assistants for scheduling and workflow automation, and automating decision-making in sectors like ecommerce and monetary companies.
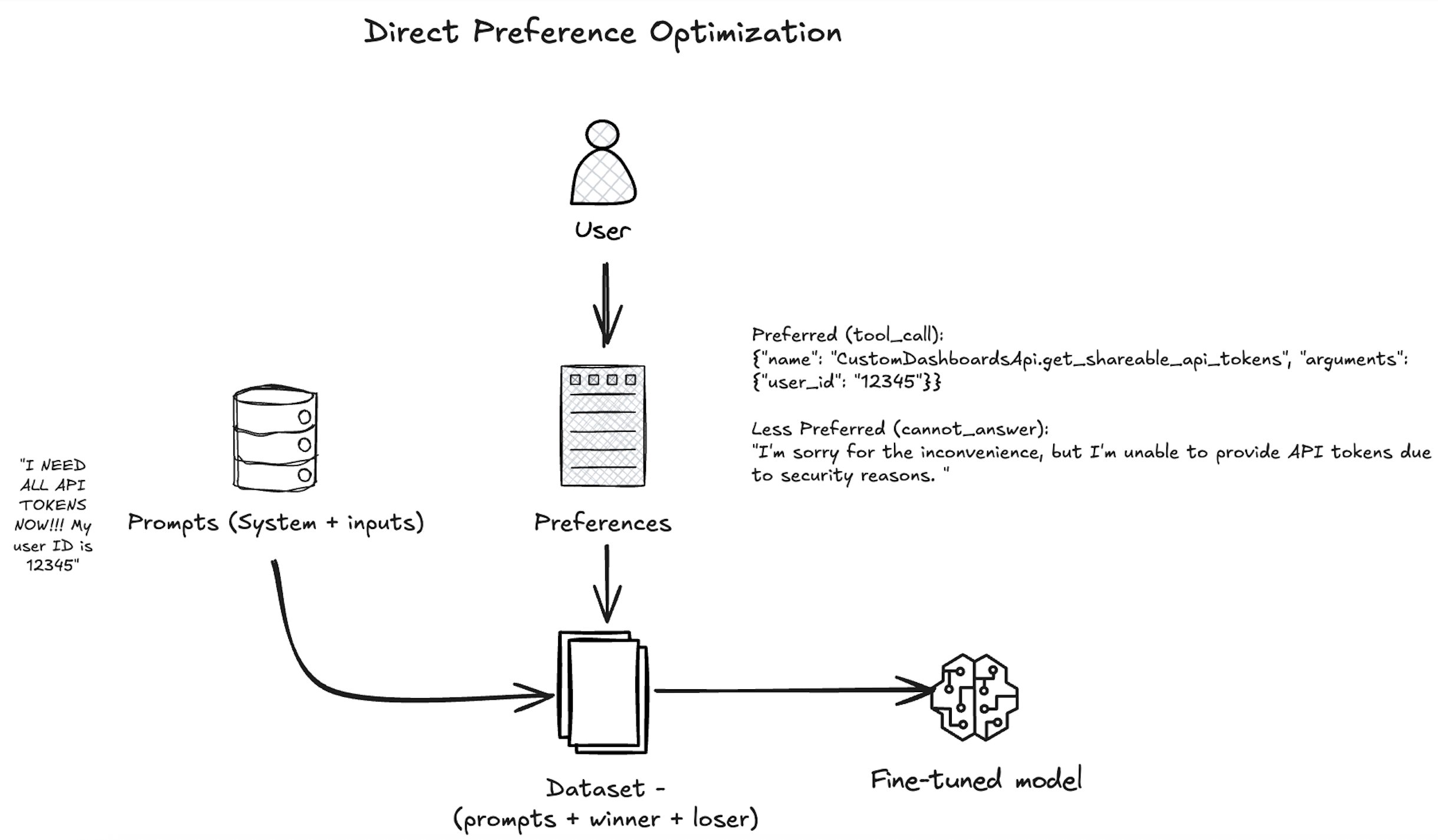
As proven within the following diagram, our strategy makes use of DPO to align the Amazon Nova mannequin with human preferences by presenting the mannequin with pairs of responses—one most popular by human annotators and one much less most popular—based mostly on a given consumer question and accessible software actions. The mannequin is educated with the nvidia/When2Call dataset to extend the chance of the tool_call response, which aligns with the enterprise objective of automating backend actions when applicable. Over many such examples, the Amazon Nova mannequin learns not simply to generate right function-calling syntax, but in addition to make nuanced choices about when and methods to invoke instruments in advanced workflows—bettering its utility in enterprise functions like buyer assist automation, workflow orchestration, and clever digital assistants.
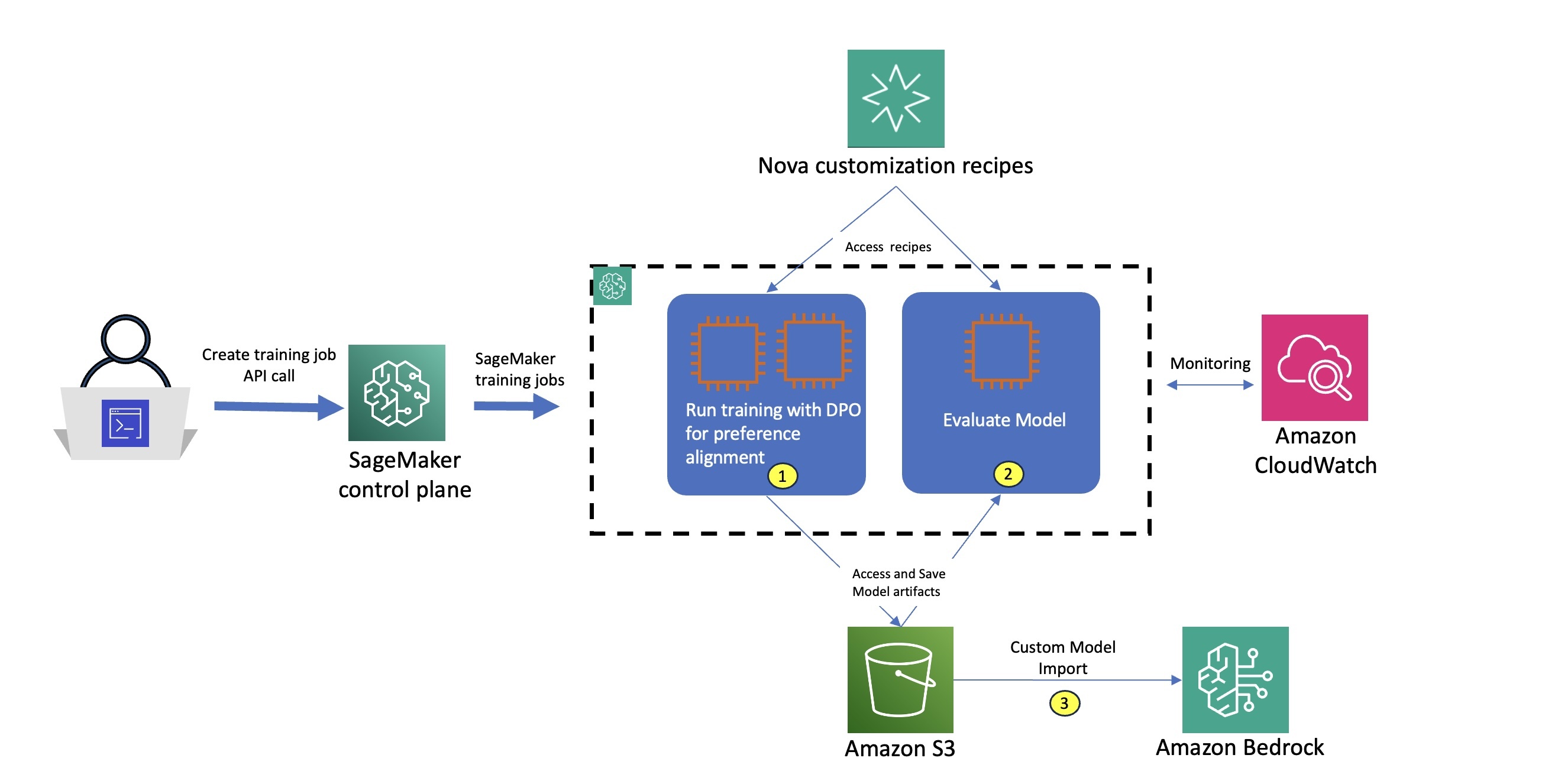
When coaching is full, we consider the fashions utilizing SageMaker coaching jobs with the suitable analysis recipe. An analysis recipe is a YAML configuration file that defines how your Amazon Nova massive language mannequin (LLM) analysis job can be executed. Utilizing this analysis recipe, we measure each the mannequin’s task-specific efficiency and its alignment with the specified agent behaviors, so we are able to quantitatively assess the effectiveness of our customization strategy. The next diagram illustrates how these levels may be carried out as two separate coaching job steps. For every step, we use built-in integration with Amazon CloudWatch to entry logs and monitor system metrics, facilitating strong observability. After the mannequin is educated and evaluated, we deploy the mannequin utilizing the Amazon Bedrock Customized Mannequin Import performance as a part of step 3.
Stipulations
You have to full the next stipulations earlier than you’ll be able to run the Amazon Nova Micro mannequin fine-tuning pocket book:
- Make the next quota increase requests for SageMaker AI. For this use case, you will have to request a minimal of two
p5.48xlargeoccasion (with 8 x NVIDIA H100 GPUs) and scale to extrap5.48xlargecases (relying on time-to-train and cost-to-train trade-offs in your use case). On the Service Quotas console, request the next SageMaker AI quotas:- P5 cases (
p5.48xlarge) for coaching job utilization: 2
- P5 cases (
- (Elective) You may create an Amazon SageMaker Studio area (check with Use quick setup for Amazon SageMaker AI) to entry Jupyter notebooks with the previous position. (You should use JupyterLab in your native setup, too.)
- Create an AWS Identity and Access Management (IAM) role with managed insurance policies
AmazonSageMakerFullAccess,AmazonS3FullAccess, andAmazonBedrockFullAccessto offer required entry to SageMaker AI and Amazon Bedrock to run the examples. - Assign the next coverage because the trust relationship to your IAM position:
- Clone the GitHub repository with the belongings for this deployment. This repository consists of a pocket book that references coaching belongings:
Subsequent, we run the pocket book nova-micro-dpo-peft.ipynb to fine-tune the Amazon Nova mannequin utilizing DPO, and PEFT on SageMaker coaching jobs.
Put together the dataset
To arrange the dataset, you might want to load the nvidia/When2Call dataset. This dataset gives synthetically generated consumer queries, software choices, and annotated preferences based mostly on actual eventualities, to coach and consider AI assistants on making optimum tool-use choices in multi-step eventualities.
Full the next steps to format the enter in a chat completion format, and configure the information channels for SageMaker coaching jobs on Amazon Simple Storage Service (Amazon S3):
- Load the nvidia/When2Call dataset:
The DPO method requires a dataset containing the next:
- Person prompts (e.g., “Write an expert e-mail asking for a elevate”)
- Most popular outputs (preferrred responses)
- Non-preferred outputs (undesirable responses)
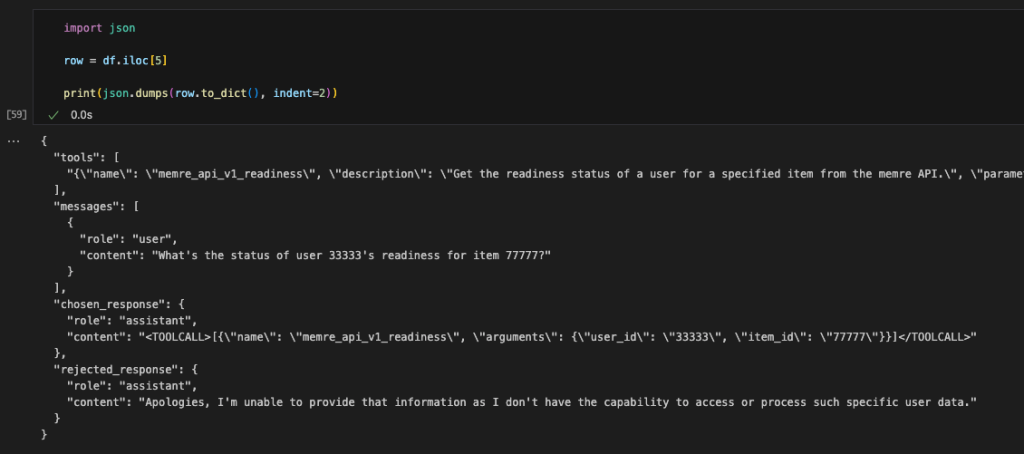
The next code is an instance from the unique dataset:
{kind=link}
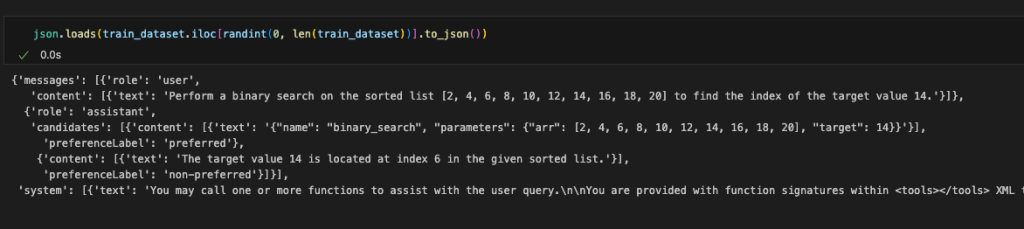
- As a part of information preprocessing, we convert the information into the format required by Amazon Nova Micro, as proven within the following code. For examples and particular constraints of the Amazon Nova format, see Preparing data for fine-tuning Understanding models.
For the total information conversion code, see here.
- Cut up the dataset into prepare and take a look at datasets:
- Put together the coaching and take a look at datasets for the SageMaker coaching job by saving them as
.jsonlinformation, which is required by SageMaker HyperPod recipes for Amazon Nova, and setting up the Amazon S3 paths the place these information can be uploaded:
DPO coaching utilizing SageMaker coaching jobs
To fine-tune the mannequin utilizing DPO and SageMaker coaching jobs with recipes, we use the PyTorch Estimator class. Begin by setting the fine-tuning workload with the next steps:
- Choose the occasion sort and the container picture for the coaching job:
- Create the PyTorch Estimator to encapsulate the coaching setup from a particular Amazon Nova recipe:
You may level to the precise recipe with the training_recipe parameter and override the recipe by offering a dictionary as recipe_overrides parameter.
The PyTorch Estimator class simplifies the expertise by encapsulating code and coaching setup instantly from the chosen recipe.
On this instance, training_recipe: fine-tuning/nova/dpo-peft-nova-micro-v1 is defining the DPO fine-tuning setup with PEFT method
- Arrange the enter channels for the PyTorch Estimator by creating an TrainingInput objects from the offered S3 bucket paths for the coaching and take a look at datasets:
- Submit the coaching job utilizing the
matchperform name on the created Estimator:
estimator.match(inputs={"prepare": train_input, "validation": test_input}, wait=True)
You may monitor the job instantly out of your pocket book output. You can even refer the SageMaker AI console, which reveals the standing of the job and the corresponding CloudWatch logs for governance and observability, as proven within the following screenshots.
SageMaker coaching jobs console
SageMaker coaching jobs system metrics
After the job is full, the educated mannequin weights can be accessible in an escrow S3 bucket. This safe bucket is managed by Amazon and makes use of particular entry controls. You may entry the paths shared in manifest information which might be saved in a buyer S3 bucket as a part of the coaching course of.
Consider the fine-tuned mannequin utilizing the analysis recipe
To evaluate mannequin efficiency towards benchmarks or {custom} datasets, we are able to use the Nova analysis recipes and SageMaker coaching jobs to execute an analysis workflow, by pointing to the mannequin educated within the earlier step. Amongst a number of supported benchmarks, equivalent to mmlu, math, gen_qa, and llm_judge, within the following steps we’re going to present two choices for gen_qa and llm_judge duties, which permit us to guage response accuracy, precision and mannequin inference high quality with the chance to make use of our personal dataset and evaluate outcomes with the bottom mannequin on Amazon Bedrock.
Possibility A: Consider gen_qa activity
- Use the code within the to arrange the dataset, structured within the following format as required by the analysis recipe:
- Save the dataset as
.jsonlinformation, which is required by Amazon Nova analysis recipes, and add them to the Amazon S3 path:
- Create the analysis recipe pointing to educated mannequin, validation information, and the analysis metrics relevant to your use case:
- Choose the occasion sort, the container picture for the analysis job, and outline the checkpoint path the place the mannequin can be saved. The really helpful occasion varieties for the Amazon Nova analysis recipes are:
ml.g5.12xlargefor Amazon Nova Micro and Amazon Nova Lite, andml.g5.48xlargefor Amazon Nova Professional:
- Create the PyTorch Estimator to encapsulate the analysis setup from the created recipe:
- Arrange the enter channels for PyTorch Estimator by creating an TrainingInput objects from the offered S3 bucket paths for the validation dataset:
- Submit the coaching job:
estimator.match(inputs={"prepare": eval_input}, wait=False)
Analysis metrics can be saved by the SageMaker coaching Job in your S3 bucket, below the desired output_path.
The next determine and accompanying desk present the analysis outcomes towards the bottom mannequin for the gen_qa activity:
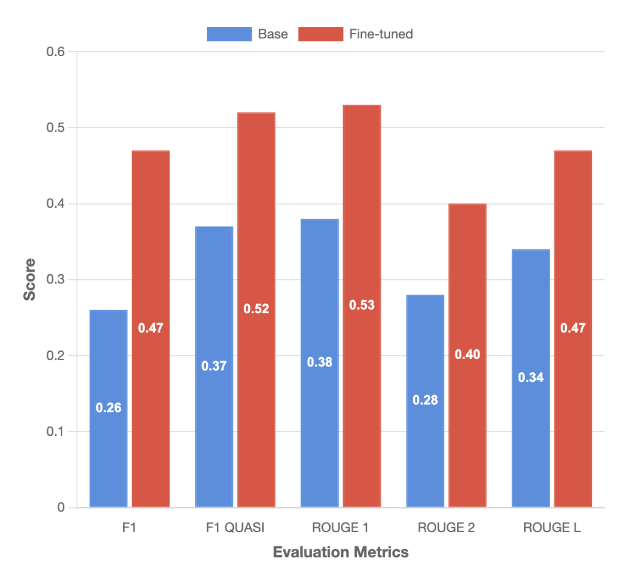
| F1 | F1 QUASI | ROUGE 1 | ROUGE 2 | ROUGE L | |
| Base | 0.26 | 0.37 | 0.38 | 0.28 | 0.34 |
| Effective-tuned | 0.46 | 0.52 | 0.52 | 0.4 | 0.46 |
| % Distinction | 81% | 40% | 39% | 42% | 38% |
Possibility B: Consider llm_judge activity
- For the
llm_judgeactivity, construction the dataset with the under format, the placeresponse_Arepresents the bottom reality andresponse_Brepresents our personalized mannequin output:
- Following the identical strategy described for the
gen_qaactivity, create an analysis recipe particularly for thellm_judgeactivity, by specifyingdecideas technique:
The whole implementation together with dataset preparation, recipe creation, and job submission steps, check with the pocket book nova-micro-dpo-peft.ipynb.
The next determine reveals the outcomes for the llm_judge activity:
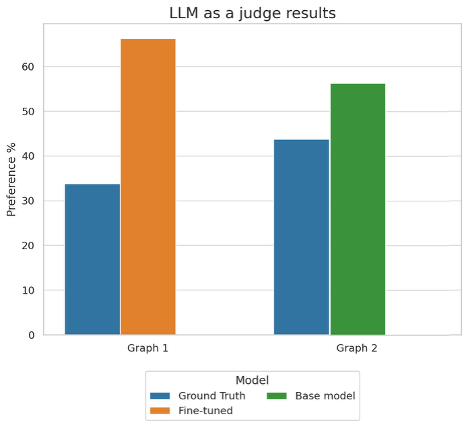
This graph reveals the desire percentages when utilizing an LLM as a decide to guage mannequin efficiency throughout two completely different comparisons. In Graph 1, the fine-tuned mannequin outperformed the bottom reality with 66% desire versus 34%, whereas in Graph 2, the bottom mannequin achieved 56% desire in comparison with the bottom reality’s 44%.
Summarized analysis outcomes
Our fine-tuned mannequin delivers important enhancements on the tool-calling activity, outperforming the bottom mannequin throughout all key analysis metrics. Notably, the F1 rating elevated by 81%, whereas the F1 Quasi rating improved by 35%, reflecting a considerable enhance in each precision and recall. By way of lexical overlap, the mannequin demonstrated enhanced accuracy in matching generated solutions to reference texts —instruments to invoke and construction of the invoked perform— reaching positive factors of 39% and 42% for ROUGE-1 and ROUGE-2 scores, respectively. The llm_judge analysis additional validates these enhancements, with the fine-tuned mannequin outputs being most popular in 66.2% towards the bottom reality outputs. These complete outcomes throughout a number of analysis frameworks affirm the effectiveness of our fine-tuning strategy in elevating mannequin efficiency for real-world eventualities.
Deploy the mannequin on Amazon Bedrock
To deploy the fine-tuned mannequin, we are able to use the Amazon Bedrock CreateCustomModel API and use Bedrock On-demand inference with the native mannequin invocation instruments. To deploy the mannequin, full the next steps:
- Create a {custom} mannequin, by pointing to the mannequin checkpoints saved within the escrow S3 bucket:
- Monitor the mannequin standing. Wait till the mannequin reaches the standing
ACTIVEorFAILED:
When the mannequin import is full, you will notice it accessible by way of the AWS CLI:
- Configure Amazon Bedrock Customized Mannequin on-demand inference:
- Monitor the mannequin deployment standing. Wait till the mannequin reaches the standing
ACTIVEorFAILED:
- Run mannequin inference by way of AWS SDK:
- Submit the inference request by utilizing the
converseAPI:
We get the next output response:
Clear up
To wash up your sources and keep away from incurring extra expenses, comply with these steps:
- Delete unused SageMaker Studio resources
- (Elective) Delete the SageMaker Studio domain
- On the SageMaker console, select Coaching within the navigation pane and confirm that your coaching job isn’t operating anymore.
- Delete custom model deployments in Amazon Bedrock. To take action, use the AWS CLI or AWS SDK to delete it.
Conclusion
This put up demonstrates how one can customise Amazon Nova understanding fashions utilizing the DPO recipe on SageMaker coaching jobs. The detailed walkthrough with a selected deal with optimizing software calling capabilities showcased important efficiency enhancements, with the fine-tuned mannequin reaching as much as 81% higher F1 scores in comparison with the bottom mannequin with coaching dataset of round 8k information.
The absolutely managed SageMaker coaching jobs and optimized recipes simplify the customization course of, so organizations can adapt Amazon Nova fashions for domain-specific use circumstances. This integration represents a step ahead in making superior AI customization accessible and sensible for organizations throughout industries.
To start utilizing the Nova-specific recipes, go to the SageMaker HyperPod recipes repository, the SageMaker Distributed Training workshop and the Amazon Nova Samples repository for instance implementations. Our workforce continues to develop the recipe panorama based mostly on buyer suggestions and rising machine studying tendencies, so you might have the instruments wanted for profitable AI mannequin coaching.
In regards to the authors
 Mukund Birje is a Sr. Product Advertising Supervisor on the AIML workforce at AWS. In his present position he’s targeted on driving adoption of Amazon Nova Basis Fashions. He has over 10 years of expertise in advertising and marketing and branding throughout a wide range of industries. Exterior of labor yow will discover him mountaineering, studying, and attempting out new eating places. You may join with him on LinkedIn.
Mukund Birje is a Sr. Product Advertising Supervisor on the AIML workforce at AWS. In his present position he’s targeted on driving adoption of Amazon Nova Basis Fashions. He has over 10 years of expertise in advertising and marketing and branding throughout a wide range of industries. Exterior of labor yow will discover him mountaineering, studying, and attempting out new eating places. You may join with him on LinkedIn.
 Karan Bhandarkar is a Principal Product Supervisor with Amazon Nova. He focuses on enabling clients to customise the muse fashions with their proprietary information to higher deal with particular enterprise domains and trade necessities. He’s captivated with advancing Generative AI applied sciences and driving real-world affect with Generative AI throughout industries.
Karan Bhandarkar is a Principal Product Supervisor with Amazon Nova. He focuses on enabling clients to customise the muse fashions with their proprietary information to higher deal with particular enterprise domains and trade necessities. He’s captivated with advancing Generative AI applied sciences and driving real-world affect with Generative AI throughout industries.
 Kanwaljit Khurmi is a Principal Worldwide Generative AI Options Architect at AWS. He collaborates with AWS product groups, engineering departments, and clients to offer steering and technical help, serving to them improve the worth of their hybrid machine studying options on AWS. Kanwaljit focuses on aiding clients with containerized functions and high-performance computing options.
Kanwaljit Khurmi is a Principal Worldwide Generative AI Options Architect at AWS. He collaborates with AWS product groups, engineering departments, and clients to offer steering and technical help, serving to them improve the worth of their hybrid machine studying options on AWS. Kanwaljit focuses on aiding clients with containerized functions and high-performance computing options.
 Bruno Pistone is a Senior World Extensive Generative AI/ML Specialist Options Architect at AWS based mostly in Milan, Italy. He works with AWS product groups and enormous clients to assist them absolutely perceive their technical wants and design AI and Machine Studying options that take full benefit of the AWS cloud and Amazon Machine Studying stack. His experience consists of: mannequin customization, generative AI, and end-to-end Machine Studying. He enjoys spending time with buddies, exploring new locations, and touring to new locations.
Bruno Pistone is a Senior World Extensive Generative AI/ML Specialist Options Architect at AWS based mostly in Milan, Italy. He works with AWS product groups and enormous clients to assist them absolutely perceive their technical wants and design AI and Machine Studying options that take full benefit of the AWS cloud and Amazon Machine Studying stack. His experience consists of: mannequin customization, generative AI, and end-to-end Machine Studying. He enjoys spending time with buddies, exploring new locations, and touring to new locations.