
{kind=link}
As information turns into extra ample and knowledge programs develop in complexity, stakeholders want options that reveal high quality insights. Making use of rising applied sciences to the geospatial area gives a singular alternative to create transformative consumer experiences and intuitive workstreams for customers and organizations to ship on their missions and duties.
On this submit, we discover how one can combine current programs with Amazon Bedrock to create new workflows to unlock efficiencies insights. This integration can profit technical, nontechnical, and management roles alike.
Introduction to geospatial information
Geospatial information is related to a place relative to Earth (latitude, longitude, altitude). Numerical and structured geospatial information codecs might be categorized as follows:
- vector information – Geographical options, equivalent to roads, buildings, or metropolis boundaries, represented as factors, traces, or polygons
- Raster information – Geographical info, equivalent to satellite tv for pc imagery, temperature, or elevation maps, represented as a grid of cells
- Tabular information – Location-based information, equivalent to descriptions and metrics (common rainfall, inhabitants, possession), represented in a desk of rows and columns
Geospatial information sources may also include pure language textual content parts for unstructured attributes and metadata for categorizing and describing the report in query. Geospatial Info Programs (GIS) present a approach to retailer, analyze, and show geospatial info. In GIS functions, this info is often offered with a map to visualise streets, buildings, and vegetation.
LLMs and Amazon Bedrock
Giant language fashions (LLMs) are a subset of basis fashions (FMs) that may remodel enter (often textual content or picture, relying on mannequin modality) into outputs (typically textual content) via a course of referred to as technology. Amazon Bedrock is a complete, safe, and versatile service for constructing generative AI functions and brokers.
LLMs work in lots of generalized duties involving pure language. Some frequent LLM use instances embrace:
- Summarization – Use a mannequin to summarize textual content or a doc.
- Q&A – Use a mannequin to reply questions on information or information from context supplied throughout coaching or inference utilizing Retrieval Augmented Era (RAG).
- Reasoning – Use a mannequin to offer chain of thought reasoning to help a human with decision-making and speculation analysis.
- Information technology – Use a mannequin to generate artificial information for testing simulations or hypothetical situations.
- Content material technology – Use a mannequin to draft a report from insights derived from an Amazon Bedrock information base or a consumer’s immediate.
- AI agent and power orchestration – Use a mannequin to plan the invocation of different programs and processes. After different programs are invoked by an agent, the agent’s output can then be used as context for additional LLM technology.
GIS can implement these capabilities to create worth and enhance consumer experiences. Advantages can embrace:
- Dwell decision-making – Taking real-time insights to assist speedy decision-making, equivalent to emergency response coordination and visitors administration
- Analysis and evaluation – In-depth evaluation that people or programs can establish, equivalent to development evaluation, patterns and relationships, and environmental monitoring
- Planning – Utilizing analysis and evaluation for knowledgeable long-term decision-making, equivalent to infrastructure improvement, useful resource allocation, and environmental regulation
Augmenting GIS and workflows with LLM capabilities results in easier evaluation and exploration of knowledge, discovery of recent insights, and improved decision-making. Amazon Bedrock supplies a approach to host and invoke fashions in addition to combine the AI fashions with surrounding infrastructure, which we elaborate on on this submit.
Combining GIS and AI via RAG and agentic workflows
LLMs are skilled with giant quantities of generalized info to find patterns in how language is produced. To enhance the efficiency of LLMs for particular use instances, approaches equivalent to RAG and agentic workflows have been created. Retrieving insurance policies and common information for geospatial use instances might be completed with RAG, whereas calculating and analyzing GIS information would require an agentic workflow. On this part, we broaden upon each RAG and agentic workflows within the context of geospatial use instances.
Retrieval Augmented Era
With RAG, you may dynamically inject contextual info from a information base throughout mannequin invocation.
RAG dietary supplements a user-provided immediate with information sourced from a information base (assortment of paperwork). Amazon Bedrock gives managed information bases to information sources, equivalent to Amazon Simple Storage Service (Amazon S3) and SharePoint, so you may present supplemental info, equivalent to metropolis improvement plans, intelligence reviews, or insurance policies and laws, when your AI assistant is producing a response for a consumer.
Information bases are perfect for unstructured paperwork with info saved in pure language. When your AI mannequin responds to a consumer with info sourced from RAG, it will probably present references and citations to its supply materials. The next diagram reveals how the programs join collectively.
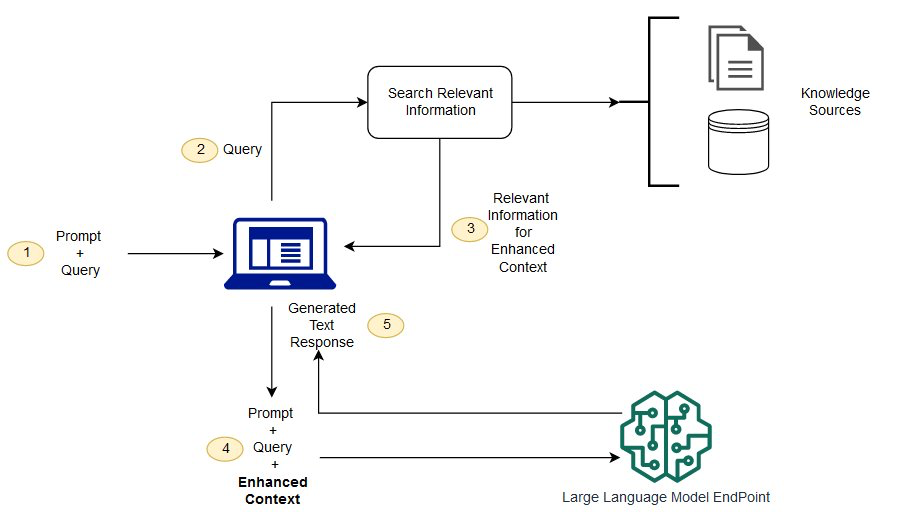
As a result of geospatial information is commonly structured and in a GIS, you may join the GIS to the LLM utilizing instruments and brokers as a substitute of data bases.
Instruments and brokers (to regulate a UI and a system)
Many LLMs, equivalent to Anthropic’s Claude on Amazon Bedrock, make it attainable to offer an outline of instruments out there so your AI mannequin can generate textual content to invoke exterior processes. These processes would possibly retrieve dwell info, equivalent to the present climate in a location or querying a structured information retailer, or would possibly management exterior programs, equivalent to beginning a workflow or including layers to a map. Some frequent geospatial performance that you just would possibly need to combine along with your LLM utilizing instruments embrace:
- Performing mathematical calculations like the space between coordinates, filtering datasets based mostly on numeric values, or calculating derived fields
- Deriving info from predictive evaluation fashions
- Trying up factors of curiosity in structured information shops
- Looking out content material and metadata in unstructured information shops
- Retrieving real-time geospatial information, like visitors, instructions, or estimated time to achieve a vacation spot
- Visualizing distances, factors of curiosity, or paths
- Submitting work outputs equivalent to analytic reviews
- Beginning workflows, like ordering provides or adjusting provide chain
Instruments are sometimes carried out in AWS Lambda capabilities. Lambda runs code with out the complexity and overhead of operating servers. It handles the infrastructure administration, enabling sooner improvement, improved efficiency, enhanced safety, and cost-efficiency.
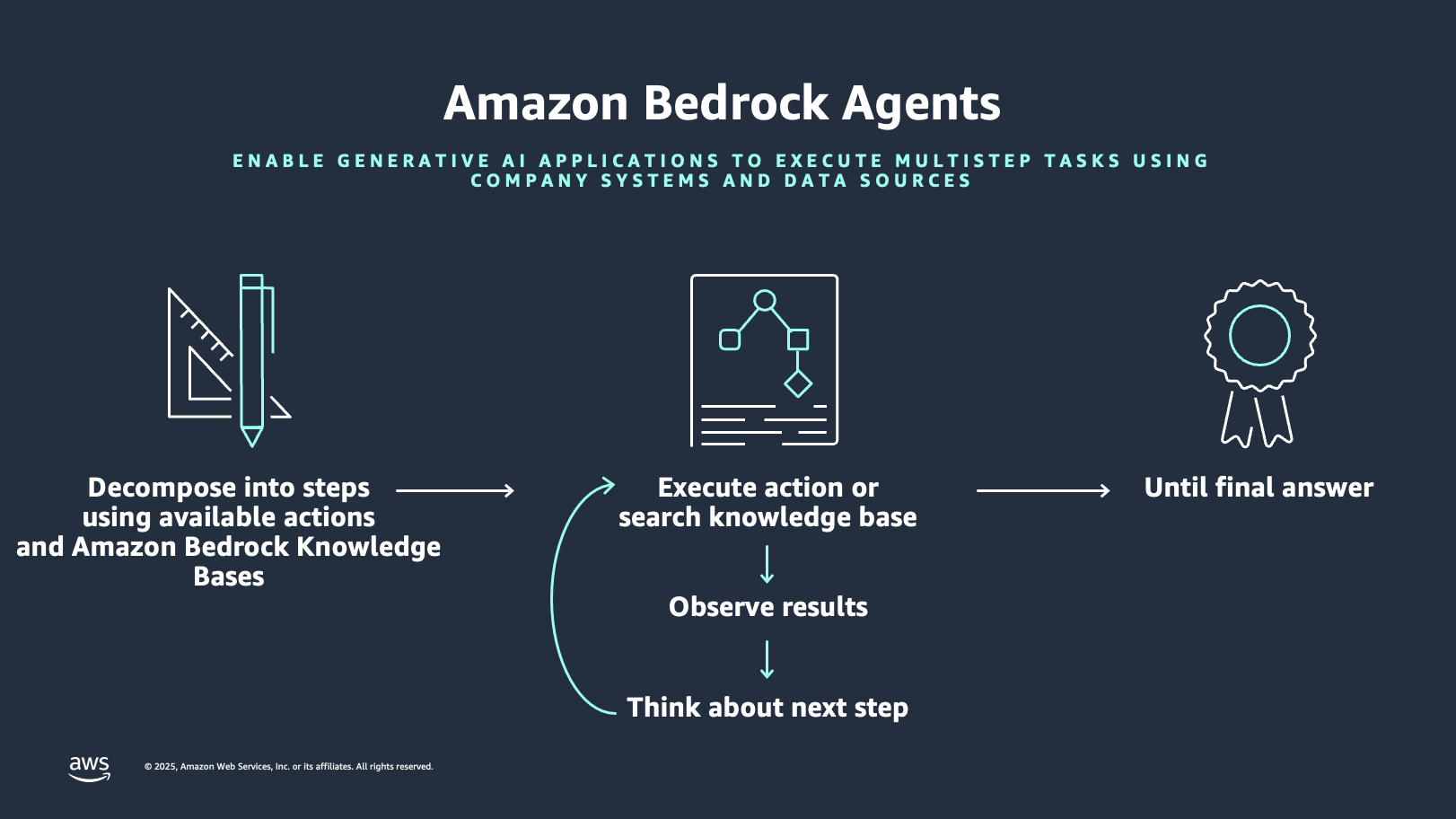
Amazon Bedrock gives the function Amazon Bedrock Agents to simplify the orchestration and integration along with your geospatial instruments. Amazon Bedrock brokers comply with directions for LLM reasoning to interrupt down a consumer immediate into smaller duties and carry out actions towards recognized duties from motion suppliers. The next diagram illustrates how Amazon Bedrock Brokers works.
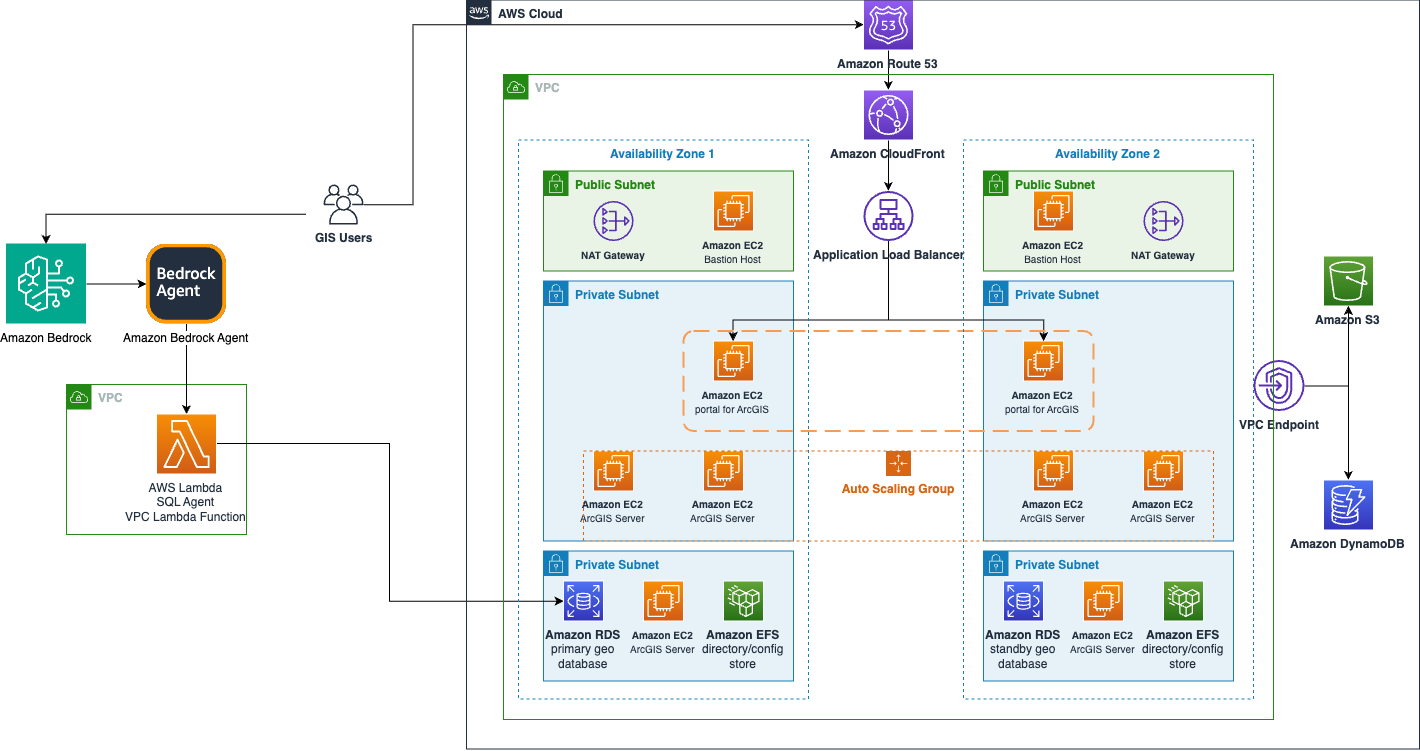
The next diagram reveals how Amazon Bedrock Brokers can improve GIS options.
Resolution overview
The next demonstration applies the ideas we’ve mentioned to an earthquake evaluation agent for instance. This instance deploys an Amazon Bedrock agent with a information base based mostly on Amazon Redshift. The Redshift occasion has two tables. One desk is for earthquakes, which incorporates date, magnitude, latitude, and longitude. The second desk holds the counites in California, described as polygon shapes. The geospatial capabilities of Amazon Redshift can relate these datasets to reply queries like which county had the latest earthquake or which county has had probably the most earthquakes within the final 20 years. The Amazon Bedrock agent can generate these geospatially based mostly queries based mostly on pure language.
This script creates an end-to-end pipeline that performs the next steps:
- Processes geospatial information.
- Units up cloud infrastructure.
- Masses and configures the spatial database.
- Creates an AI agent for spatial evaluation.
Within the following sections, we create this agent and check it out.
Conditions
To implement this strategy, you need to have an AWS account with the suitable AWS Identity and Access Management (IAM) permissions for Amazon Bedrock, Amazon Redshift, and Amazon S3.
Moreover, full the next steps to arrange the AWS Command Line Interface (AWS CLI):
- Affirm you may have entry to the newest model of the AWS CLI.
- Sign in to the AWS CLI along with your credentials.
- Make certain ./jq is put in. If not, use the next command:
Arrange error dealing with
Use the next code for the preliminary setup and error dealing with:
This code performs the next capabilities:
- Creates a timestamped log file
- Units up error trapping that captures line numbers
- Permits computerized script termination on errors
- Implements detailed logging of failures
Validate the AWS setting
Use the next code to validate the AWS setting:
This code performs the important AWS setup verification:
- Checks AWS CLI set up
- Validates AWS credentials
- Retrieves account ID for useful resource naming
Arrange Amazon Redshift and Amazon Bedrock variables
Use the next code to create Amazon Redshift and Amazon Bedrock variables:
Create IAM roles for Amazon Redshift and Amazon S3
Use the next code to arrange IAM roles for Amazon S3 and Amazon Redshift:
Put together the info and Amazon S3
Use the next code to organize the info and Amazon S3 storage:
This code units up information storage and retrieval via the next steps:
- Creates a singular S3 bucket
- Downloads earthquake and county boundary information
- Prepares for information transformation
Rework geospatial information
Use the next code to remodel the geospatial information:
This code performs the next actions to transform the geospatial information codecs:
- Transforms ESRI JSON to WKT format
- Processes county boundaries into CSV format
- Preserves spatial info for Amazon Redshift
Create a Redshift cluster
Use the next code to arrange the Redshift cluster:
This code performs the next capabilities:
- Units up a single-node cluster
- Configures networking and safety
- Waits for cluster availability
Create a database schema
Use the next code to create the database schema:
This code performs the next capabilities:
- Creates a counties desk with spatial information
- Creates an earthquakes desk
- Configures acceptable information varieties
Create an Amazon Bedrock information base
Use the next code to create a information base:
This code performs the next capabilities:
- Creates an Amazon Bedrock information base
- Units up an Amazon Redshift information supply
- Permits spatial queries
Create an Amazon Bedrock agent
Use the next code to create and configure an agent:
This code performs the next capabilities:
- Creates an Amazon Bedrock agent
- Associates the agent with the information base
- Configures the AI mannequin and directions
Take a look at the answer
Let’s observe the system conduct with the next pure language consumer inputs within the chat window.
Instance 1: Summarization and Q&A
For this instance, we use the immediate “Summarize which zones permit for constructing of an condo.”
The LLM performs retrieval with a RAG strategy, then makes use of the retrieved residential code paperwork as context to reply the consumer’s question in pure language.
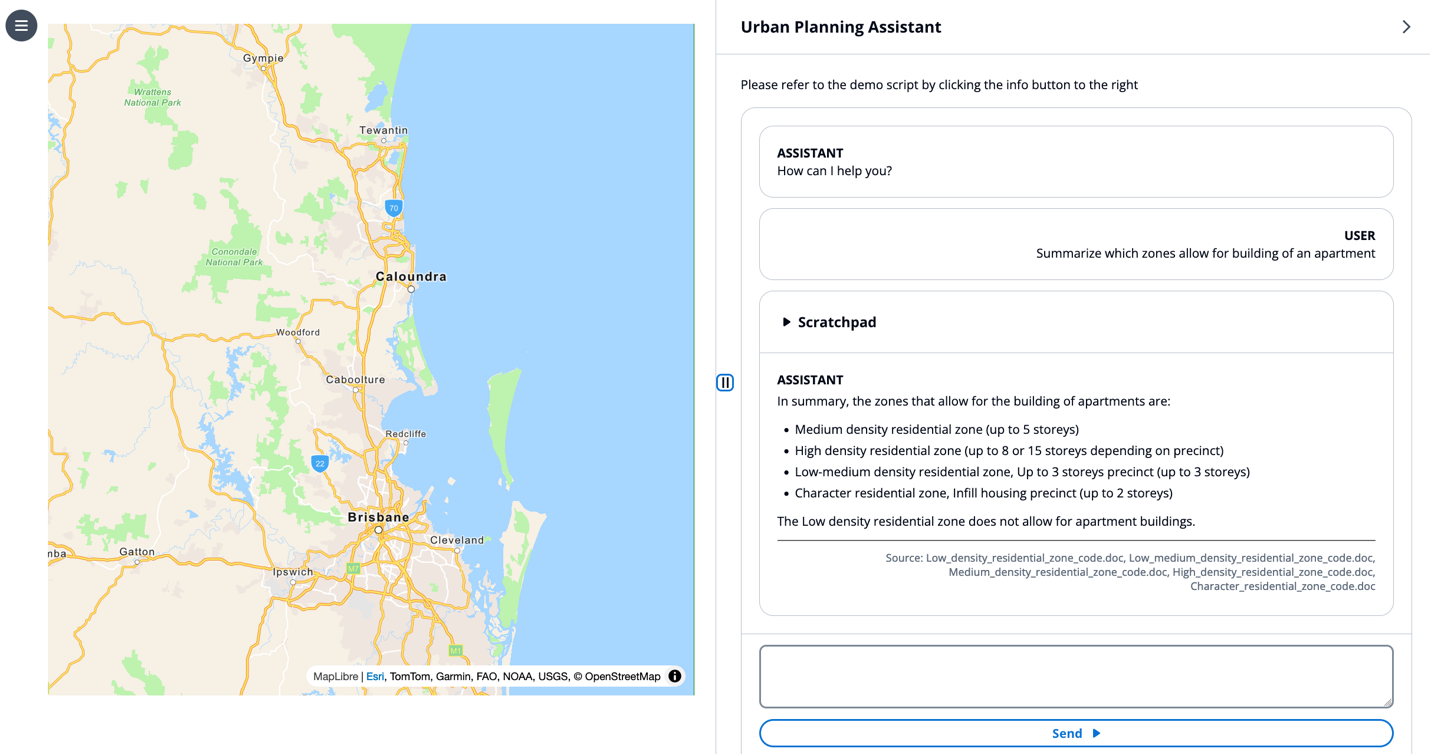
This instance demonstrates the LLM capabilities for hallucination mitigation, RAG, and summarization.
Instance 2: Generate a draft report
Subsequent, we enter the immediate “Write me a report on how numerous zones and associated housing information might be utilized to plan new housing improvement to satisfy excessive demand.”
The LLM retrieves related city planning code paperwork, then summarizes the knowledge into a typical reporting format as described in its system immediate.
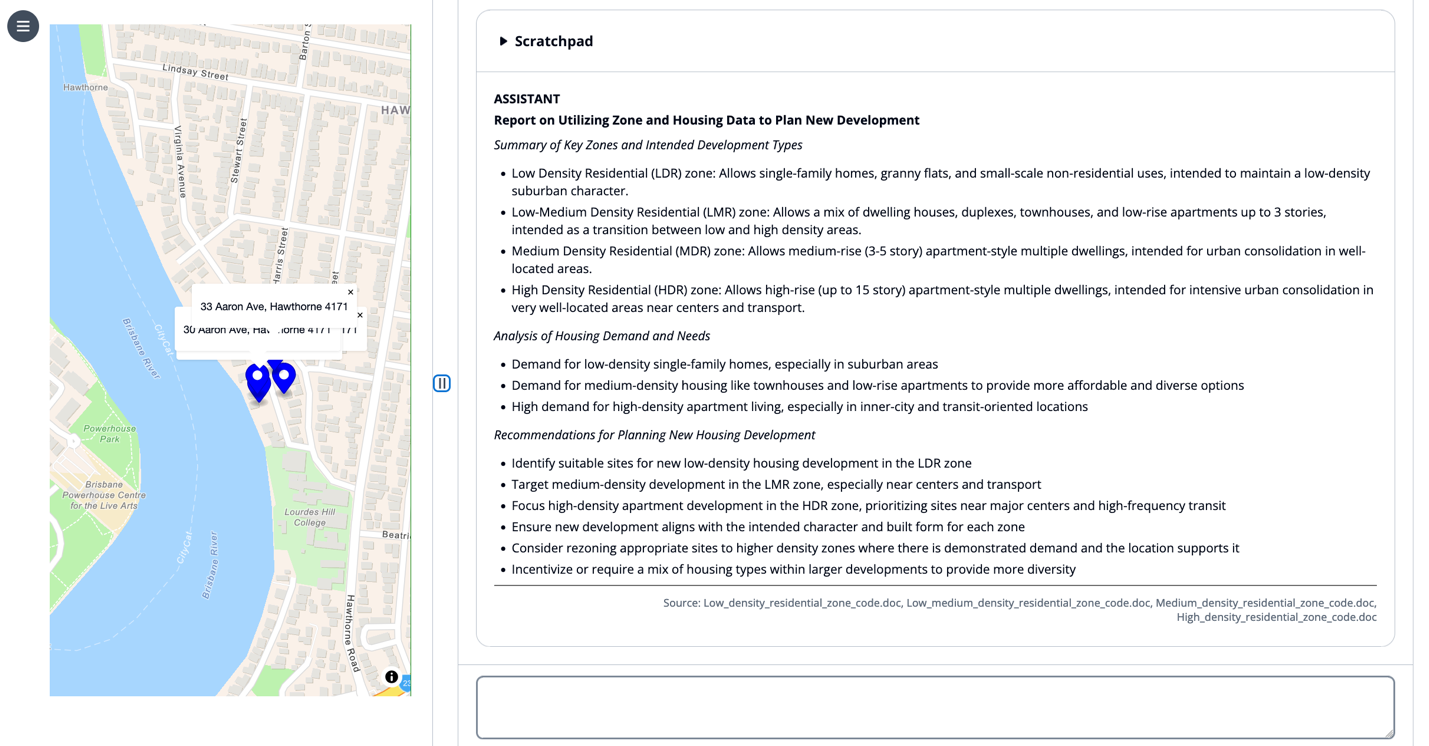
This instance demonstrates the LLM capabilities for immediate templates, RAG, and summarization.
Instance 3: Present locations on the map
For this instance, we use the immediate “Present me the low density properties on Abbeville road in Macgregor on the map with their handle.”
The LLM creates a series of thought to search for which properties match the consumer’s question after which invokes the draw marker device on the map. The LLM supplies device invocation parameters in its scratchpad, awaits the completion of those device invocations, then responds in pure language with a bulleted record of markers positioned on the map.
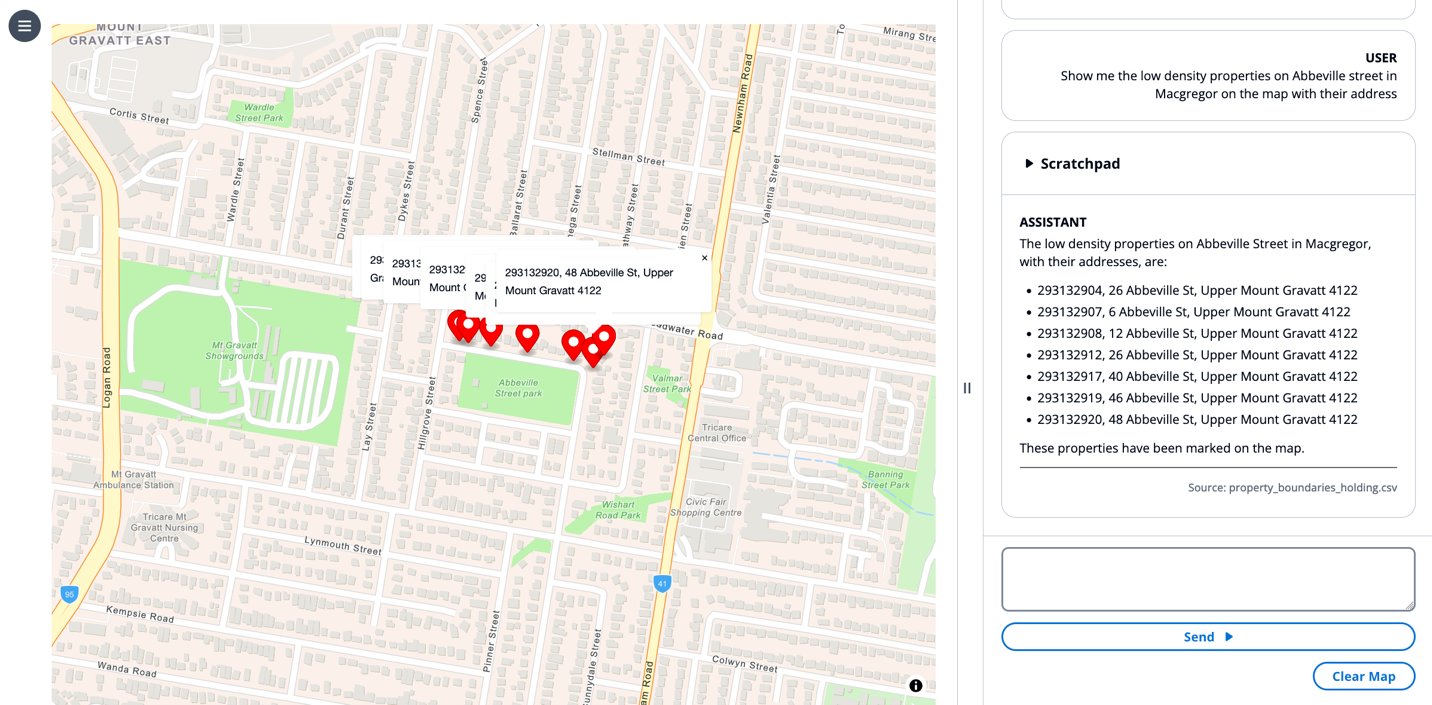
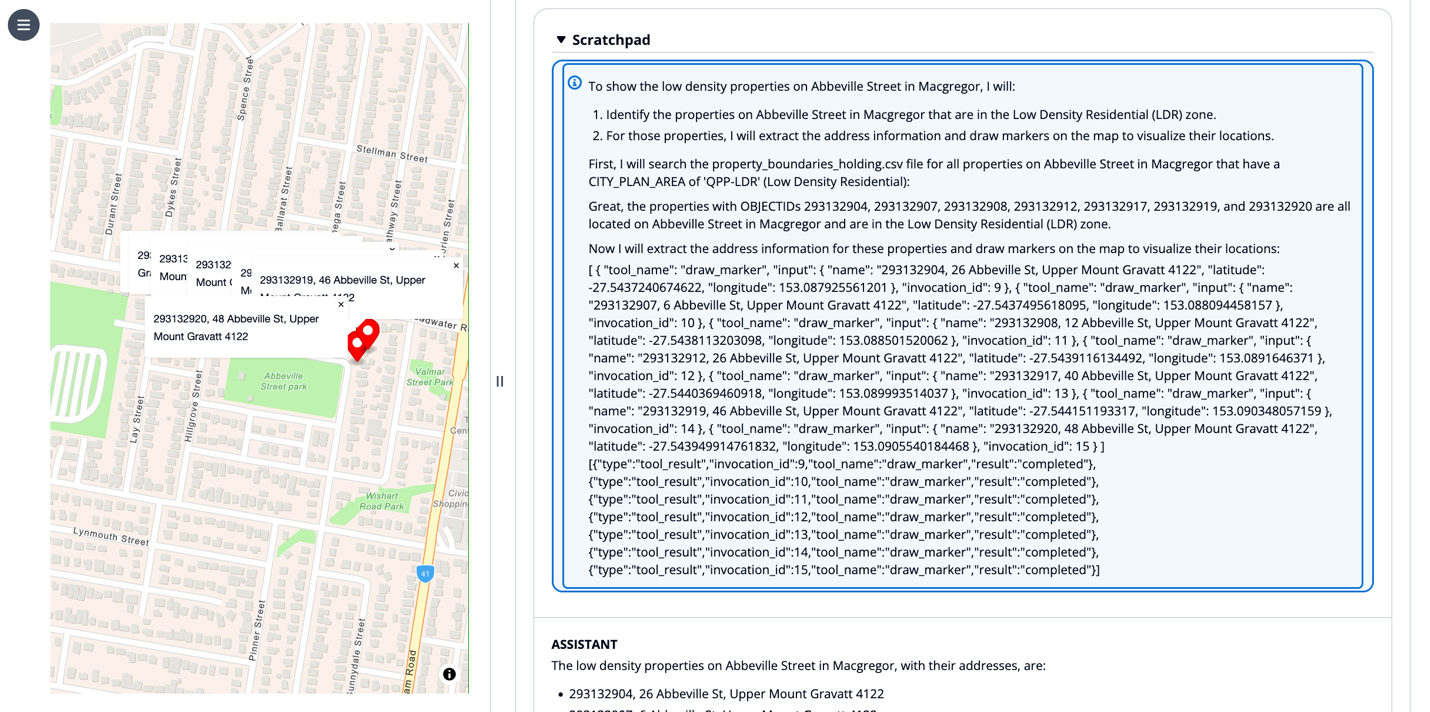
This instance demonstrates the LLM capabilities for chain of thought reasoning, device use, retrieval programs utilizing brokers, and UI management.
Instance 4: Use the UI as context
For this instance, we select a marker on a map and enter the immediate “Can I construct an condo right here.”
The “right here” just isn’t contextualized from dialog historical past however somewhat from the state of the map view. Having a state engine that may relay info from a frontend view to the LLM enter provides a richer context.
The LLM understands the context of “right here” based mostly on the chosen marker, performs retrieval to see the land improvement coverage, and responds to the consumer in easy pure language, “No, and right here is why…”
This instance demonstrates the LLM capabilities for UI context, chain of thought reasoning, RAG, and power use.
Instance 5: UI context and UI management
Subsequent, we select a marker on the map and enter the immediate “draw a .25 mile circle round right here so I can visualize strolling distance.”
The LLM invokes the draw circle device to create a layer on the map centered on the chosen marker, contextualized by “right here.”
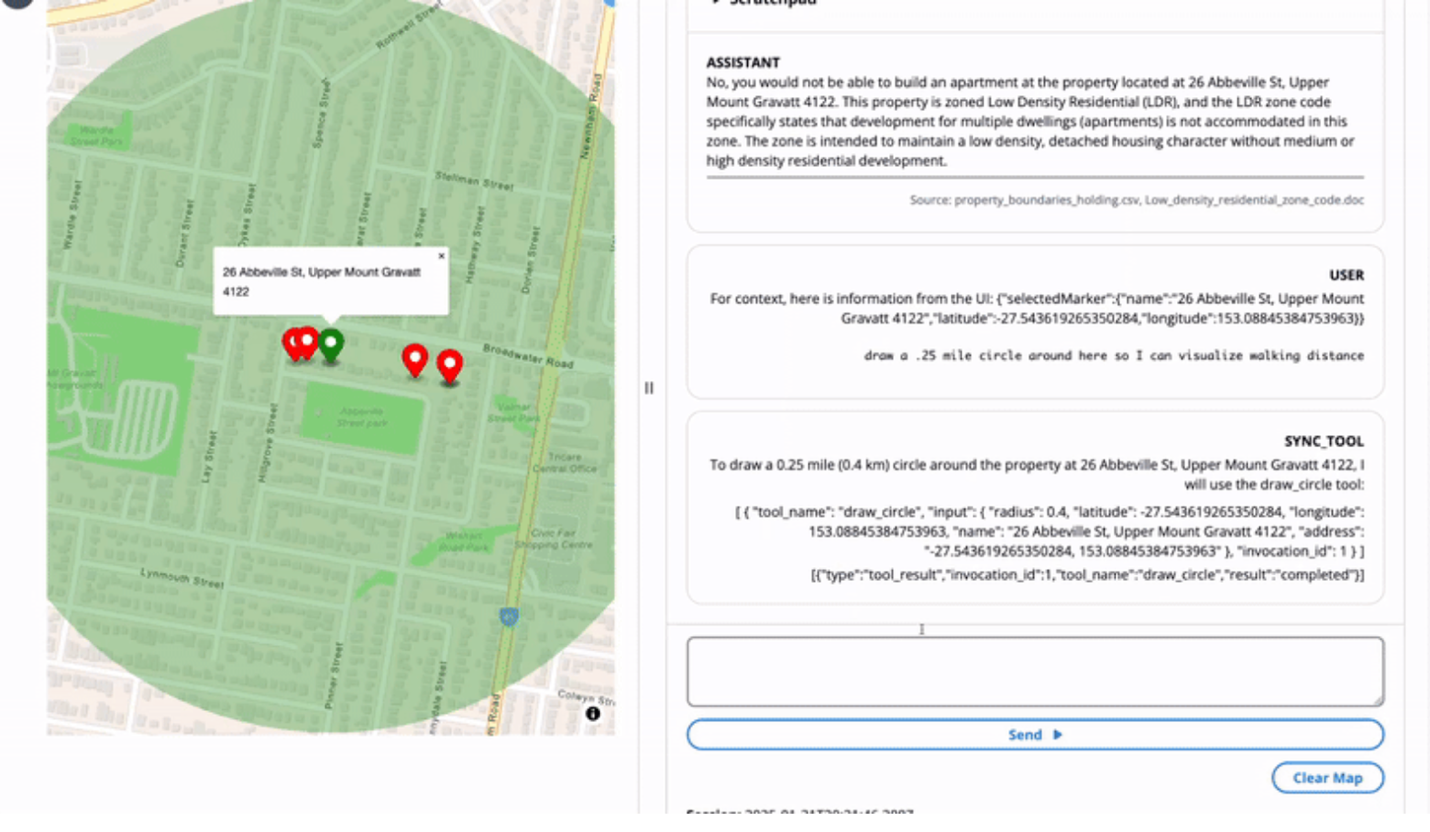
This instance demonstrates the LLM capabilities for UI context, chain of thought reasoning, device use, and UI management.
Clear up
To scrub up your assets and stop AWS fees from being incurred, full the next steps:
- Delete the Amazon Bedrock information base.
- Delete the Redshift cluster.
- Delete the S3 bucket.
Conclusion
The mixing of LLMs with GIS creates intuitive programs that assist customers of various technical ranges carry out complicated spatial evaluation via pure language interactions. Through the use of RAG and agent-based workflows, organizations can keep information accuracy whereas seamlessly connecting AI fashions to their current information bases and structured information programs. Amazon Bedrock facilitates this convergence of AI and GIS expertise by offering a strong platform for mannequin invocation, information retrieval, and system management, finally reworking how customers visualize, analyze, and work together with geographical information.
For additional exploration, Earth on AWS has movies and articles you may discover to know how AWS helps construct GIS functions on the cloud.
Concerning the Authors
 Dave Horne is a Sr. Options Architect supporting Federal System Integrators at AWS. He’s based mostly in Washington, DC, and has 15 years of expertise constructing, modernizing, and integrating programs for public sector clients. Exterior of labor, Dave enjoys taking part in together with his children, mountaineering, and watching Penn State soccer!
Dave Horne is a Sr. Options Architect supporting Federal System Integrators at AWS. He’s based mostly in Washington, DC, and has 15 years of expertise constructing, modernizing, and integrating programs for public sector clients. Exterior of labor, Dave enjoys taking part in together with his children, mountaineering, and watching Penn State soccer!
 Kai-Jia Yue is a options architect on the Worldwide Public Sector International Programs Integrator Structure workforce at Amazon Internet Providers (AWS). She has a spotlight in information analytics and serving to buyer organizations make data-driven selections. Exterior of labor, she loves spending time with family and friends and touring.
Kai-Jia Yue is a options architect on the Worldwide Public Sector International Programs Integrator Structure workforce at Amazon Internet Providers (AWS). She has a spotlight in information analytics and serving to buyer organizations make data-driven selections. Exterior of labor, she loves spending time with family and friends and touring.
 Brian Smitches is the Head of Accomplice Deployed Engineering at Windsurf specializing in how companions can carry organizational worth via the adoption of Agentic AI software program improvement instruments like Windsurf and Devin. Brian has a background in Cloud Options Structure from his time at AWS, the place he labored within the AWS Federal Accomplice ecosystem. In his private time, Brian enjoys snowboarding, water sports activities, and touring with family and friends.
Brian Smitches is the Head of Accomplice Deployed Engineering at Windsurf specializing in how companions can carry organizational worth via the adoption of Agentic AI software program improvement instruments like Windsurf and Devin. Brian has a background in Cloud Options Structure from his time at AWS, the place he labored within the AWS Federal Accomplice ecosystem. In his private time, Brian enjoys snowboarding, water sports activities, and touring with family and friends.