
{kind=link}
Giant language fashions (LLMs) now stand on the heart of numerous AI breakthroughs—chatbots, coding assistants, query answering, creative writing, and far more. However regardless of their prowess, they continue to be stateless: every question arrives with no reminiscence of what got here earlier than. Their fastened context home windows imply they will’t accumulate persistent information throughout lengthy conversations or multi-session duties, they usually battle to cause over complicated histories. Latest options, like retrieval-augmented era (RAG), append previous info to prompts, however this typically results in noisy, unfiltered context—flooding the mannequin with an excessive amount of irrelevant element or lacking essential info.
A staff of researchers from College of Munich, Technical College of Munich, College of Cambridge and College of Hong Kong launched Reminiscence-R1, a framework that teaches LLM brokers to determine what to recollect and methods to use it. Its LLM agent learns to actively handle and make the most of exterior reminiscence—deciding what so as to add, replace, delete, or ignore, and filtering out noise when answering questions. The breakthrough? It trains these behaviors with reinforcement studying (RL), utilizing solely outcome-based rewards, so it wants minimal supervision and generalizes robustly throughout fashions and duties.
However Why LLMs Wrestle with Reminiscence?
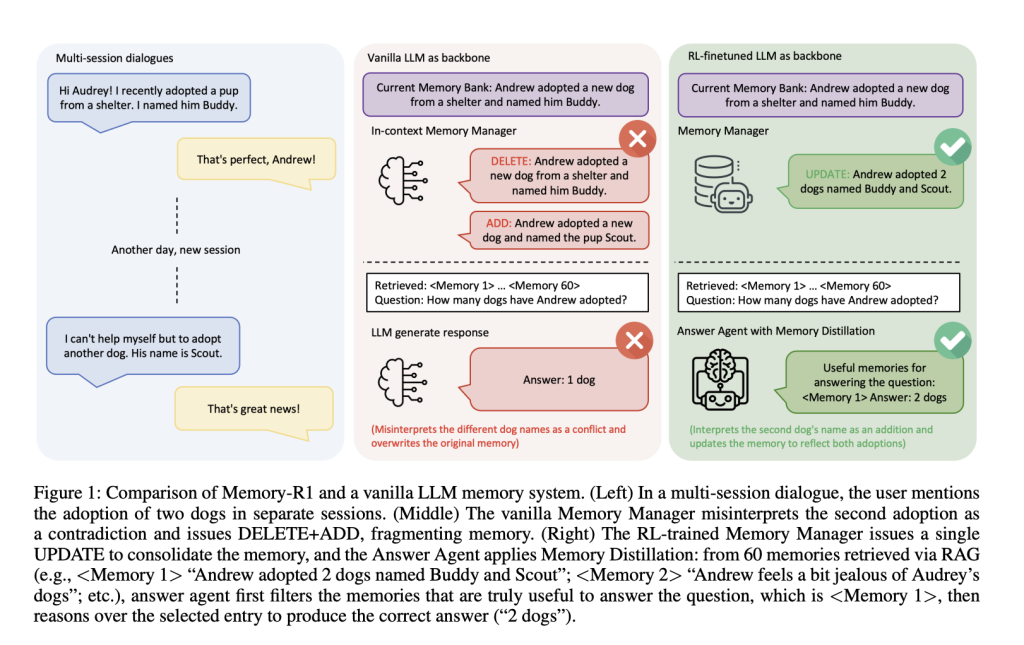
Think about a multi-session dialog: within the first session, a person says, “I adopted a canine named Buddy.” Later, they add, “I adopted one other canine named Scout.” Ought to the system change the primary assertion with the second, merge them, or ignore the replace? Vanilla reminiscence pipelines typically fail—they could erase “Buddy” and add “Scout,” misinterpreting the brand new info as a contradiction quite than a consolidation. Over time, such techniques lose coherence, fragmenting person information quite than evolving it.
RAG techniques retrieve info however don’t filter it: irrelevant entries pollute reasoning, and the mannequin will get distracted by noise. People, in contrast, retrieve extensively however then selectively filter what issues. Most AI reminiscence techniques are static, counting on handcrafted heuristics for what to recollect, quite than studying from suggestions.
The Reminiscence-R1 Framework
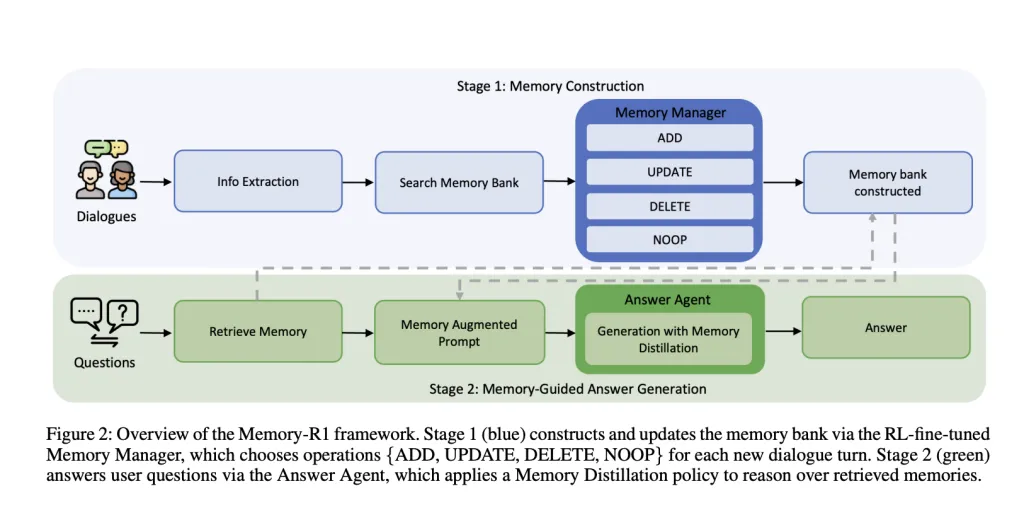
Reminiscence-R1 is constructed round two specialised, RL-fine-tuned brokers:
- Reminiscence Supervisor: Decides which reminiscence operations (ADD, UPDATE, DELETE, NOOP) to carry out after every dialogue flip, updating the exterior reminiscence financial institution dynamically.
- Reply Agent: For every person query, retrieves as much as 60 candidate recollections, distills them to essentially the most related subset, then causes over this filtered context to generate a solution.
Each parts are skilled with reinforcement studying RL—utilizing both Proximal Coverage Optimization (PPO) or Group Relative Coverage Optimization (GRPO)—with solely question-answer correctness because the reward sign. Because of this, as a substitute of requiring manually labeled reminiscence operations, the brokers study by trial and error, optimizing for last activity efficiency.
Reminiscence Supervisor: Studying to Edit Data
After every dialogue flip, an LLM extracts key info. The Reminiscence Supervisor then retrieves associated entries from the reminiscence financial institution, and chooses an operation:
- ADD: Insert new info not already current.
- UPDATE: Merge new particulars into present recollections after they elaborate or refine earlier info.
- DELETE: Take away outdated or contradictory info.
- NOOP: Go away reminiscence unchanged if nothing related is added.
Coaching: The Reminiscence Supervisor is up to date primarily based on the standard of solutions the Reply Agent generates from the newly edited reminiscence financial institution. If a reminiscence operation allows the Reply Agent to reply precisely, the Reminiscence Supervisor receives a optimistic reward. This outcome-driven reward eliminates the necessity for pricey handbook annotation of reminiscence operations.
Instance: When a person first mentions adopting a canine named Buddy, then later provides that they adopted one other canine named Scout, a vanilla system may delete “Buddy” and add “Scout,” treating it as a contradiction. The RL-trained Reminiscence Supervisor, nonetheless, updates the reminiscence: “Andrew adopted two canine, Buddy and Scout,” sustaining a coherent, evolving information base.
Ablation: RL fine-tuning improves reminiscence administration considerably—PPO and GRPO each outperform in-context, heuristic-based managers. The system learns to consolidate quite than fragment information.
Reply Agent: Selective Reasoning
For every query, the system retrieves as much as 60 candidate recollections with RAG. However as a substitute of feeding all these to the LLM, the Reply Agent first distills the set—preserving solely essentially the most related entries. Solely then does it generate a solution.
Coaching: The Reply Agent can be skilled with RL, utilizing the precise match between its reply and the gold reply because the reward. This encourages it to give attention to filtering out noise and reasoning over high-quality context.
Instance: Requested “Does John reside near a seashore or the mountains?”, a vanilla LLM may output “mountains,” influenced by irrelevant recollections. Reminiscence-R1’s Reply Agent, nonetheless, surfaces solely beach-related entries earlier than answering, resulting in an accurate “seashore” response.
Ablation: RL fine-tuning improves reply high quality over static retrieval. Reminiscence distillation (filtering out irrelevant recollections) additional boosts efficiency. The features are even bigger with a stronger reminiscence supervisor, displaying compounding enhancements.
Coaching Knowledge Effectivity
Reminiscence-R1 is data-efficient: it achieves robust outcomes with solely 152 question-answer pairs for coaching. That is attainable as a result of the agent learns from outcomes, not from hundreds of hand-labeled reminiscence operations. Supervision is saved to a minimal, and the system scales to giant, real-world dialogue histories.
The LOCOMO benchmark, used for analysis, consists of multi-turn dialogues (about 600 turns per dialogue, 26,000 tokens on common) and related QA pairs spanning single-hop, multi-hop, open-domain, and temporal reasoning—best for testing long-horizon reminiscence administration.
Experimental Outcomes
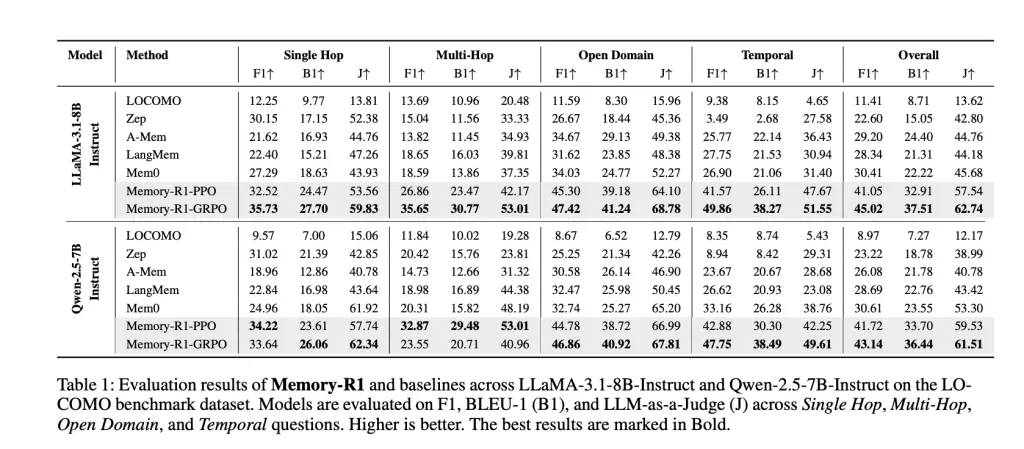
Reminiscence-R1 was examined on LLaMA-3.1-8B-Instruct and Qwen-2.5-7B-Instruct backbones, in opposition to aggressive baselines (LOCOMO, Zep, A-Mem, LangMem, Mem0). The important thing metrics are:
- F1: Measures overlap between predicted and proper solutions.
- BLEU-1: Captures lexical similarity on the unigram stage.
- LLM-as-a-Choose: Makes use of a separate LLM to guage factual accuracy, relevance, and completeness—a proxy for human judgment.
Outcomes: Reminiscence-R1-GRPO achieves the greatest general efficiency, bettering over Mem0 (the earlier greatest baseline) by 48% in F1, 69% in BLEU-1, and 37% in LLM-as-a-Choose on LLaMA-3.1-8B. Comparable features are seen on Qwen-2.5-7B. The enhancements are broad-based, spanning all query sorts, and generalize throughout mannequin architectures.
Why This Issues
Reminiscence-R1 exhibits that reminiscence administration and utilization might be discovered—LLM brokers don’t must depend on brittle heuristics. By grounding selections in outcome-driven RL, the system:
- Robotically consolidates information as conversations evolve, quite than fragmenting or overwriting it.
- Filters out noise when answering, bettering factual accuracy and reasoning high quality.
- Learns effectively with little supervision, and scales to real-world, long-horizon duties.
- Generalizes throughout fashions, making it a promising basis for the subsequent era of agentic, memory-aware AI techniques.
Conclusion
Reminiscence-R1 unshackles LLM brokers from their stateless constraints, giving them the flexibility to study—by reinforcement—methods to handle and use long-term recollections successfully. By framing reminiscence operations and filtering as RL issues, it achieves state-of-the-art efficiency with minimal supervision and robust generalization. This marks a serious step towards AI techniques that not solely converse fluently, however bear in mind, study, and cause like people—providing richer, extra persistent, and extra helpful experiences for customers all over the place.
FAQs
FAQ 1: What makes Reminiscence-R1 higher than typical LLM reminiscence techniques?
Reminiscence-R1 makes use of reinforcement studying to actively management reminiscence—deciding which info so as to add, replace, delete, or preserve—enabling smarter consolidation and fewer fragmentation than static, heuristic-based approaches.
FAQ 2: How does Reminiscence-R1 enhance reply high quality from lengthy dialogue histories?
The Reply Agent applies a “reminiscence distillation” coverage: it filters as much as 60 retrieved recollections to floor solely these most related for every query, decreasing noise and bettering factual accuracy in comparison with merely passing all context to the mannequin.
FAQ 3: Is Reminiscence-R1 data-efficient for coaching?
Sure, Reminiscence-R1 achieves state-of-the-art features utilizing solely 152 QA coaching pairs, as its outcome-based RL rewards remove the necessity for pricey handbook annotation of every reminiscence operation.
Try the Paper here. Be happy to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.