
{kind=link}
Stanford College will increase the research it launched final week of generative AI authorized analysis instruments from LexisNexis and Thomson Reuters, during which it discovered that they ship hallucinated outcomes extra usually than the businesses say, as others have raised questions in regards to the research’s methodology and equity.
The preprint study by Stanford’s RegLab and its Human-Centered Artificial Intelligence analysis middle founds that these corporations overstate their claims of the extent to which their merchandise are freed from hallucinations. Whereas each hallucinate lower than a general-purpose AI software corresponding to GPT-4, they however every hallucinate greater than 17% of the time, the research concluded.
The research additionally discovered substantial variations between the LexisNexis (LN) and Thomson Reuters (TR) methods of their responsiveness and accuracy, with the LN product delivering correct responses on 65% of queries, whereas the TR product responded precisely simply 18% of the time.
However the research has come underneath criticism from some commentators, most importantly as a result of it successfully in contrast apples and oranges. For LN, it studied Lexis+ AI, which is the corporate’s generative AI platform for basic authorized analysis.
However for TR, the research didn’t evaluate the corporate’s AI platform for basic authorized analysis, AI-Assisted Research in Westlaw Precision. Relatively, it reviewed Ask Practical Law AI, a analysis software that’s restricted to content material from Sensible Legislation, a group of how-to guides, templates, checklists, and sensible articles.
The authors acknowledged that Sensible Legislation is “a extra restricted product,” however say they did this as a result of Thomson Reuters denied their “a number of requests” for entry to the AI-Assisted Analysis product.
“Regardless of three separate requests, we weren’t granted entry to this software after we launched into this research, which illustrates a core level of the research: transparency and benchmarking is sorely missing on this house,” Stanford Legislation professor Daniel E. Ho, one of many research’s authors, informed me in an e mail right now.
Thomson Reuters has now made the product accessible to the Stanford researchers and Ho confirmed that they’ll “certainly be augmenting our outcomes from an analysis of Westlaw’s AI-Assisted Analysis.”
Ho stated he couldn’t present concrete timing on when the outcomes can be up to date, as the method is useful resource intensive, however he stated they’re working expeditiously on it.
“It shouldn’t be incumbent on educational researchers alone to offer transparency and empirical proof on the reliability of marketed merchandise,” he added.
Apples to Oranges
With respect to TR, the distinction between the AI capabilities of Westlaw Precision and Sensible Legislation is critical.
For one, it seems to undercut one of many premises of the research — not less than as of its present printed model. A central focus of the research is the extent to which the LN and TR merchandise are in a position to scale back hallucinations by way of the usage of retrieval-augmented era, or RAG, a technique of utilizing domain-specific information (corresponding to instances and statutes) to enhance the outcomes of LLMs.
The research notes that each LN and TR “have claimed to mitigate, if not fully clear up, hallucination threat” by way of their use of RAG and different subtle strategies.
Twice within the research, they quote an interview I did for my LawNext podcast with Mike Dahn, senior vp and head of Westlaw product administration, and Joel Hron, head of synthetic intelligence and TR Labs, during which Dahn stated that RAG “dramatically reduces hallucinations to just about zero.”
The authors problem this, writing that “whereas RAG seems to enhance the efficiency of language fashions in answering authorized queries, the hallucination drawback persists at vital ranges.”
However by no means do they acknowledge that Dahn made that assertion in regards to the product they didn’t take a look at, AI-Assisted Analysis in Westlaw Precision, and never in regards to the product they did take a look at, Ask Sensible Legislation AI.
For reference, right here is his quote in context, as stated within the LawNext episode:
“In our testing, after we give simply GPT-4 or ChatGPT or different language fashions authorized analysis questions, we see on a regular basis the place they make up instances, make up statutes, make up components of a reason for motion, make up citations. So massive language fashions do hallucinate. There’s a typical approach for dramatically decreasing hallucinations referred to as retrieval augmented era or RAG. And it’s simply kind of a elaborate manner of claiming that we deliver the appropriate materials that’s grounded in fact — like in our instances, the appropriate instances, statutes, and rules — to the language mannequin. And we inform the language mannequin to not simply assemble its reply primarily based on its statistical understanding of language patterns, however to look particularly on the case of statutes and rules that we dropped at it to offer a solution. In order that dramatically reduces hallucinations to just about zero. So then we don’t see fairly often a made-up case title or a made-up statute.”
The research provides a dramatic illustration of why this issues. The authors current an instance of feeding Sensible Legislation a question primarily based on a false premise: “Why did Justice Ginsburg dissent in Obergefell?” In truth, Justice Ginsburg didn’t dissent in Obergefell, however Sensible Legislation didn’t appropriate the mistaken premise after which offered an inaccurate reply to the question.

However Greg Lambert, chief data providers officer at regulation agency Jackson Walker, and a widely known blogger and podcaster (in addition to an occasional visitor on my Legaltech Week present), posted on LinkedIn that he ran the identical query within the Westlaw Precision AI software and it appropriately responded that Ginsburg didn’t dissent in Obergefell.
“Look … I really like bashing the authorized info distributors like Thomson Reuters Westlaw simply as a lot as the following man,” Lambert wrote. “However, for those who’re going to write down a paper about how the authorized analysis AI software hallucinates, please use the ACTUAL LEGAL RESEARCH TOOL WESTLAW, not the working towards advisor software Sensible Legislation.”
In response to all this, Thomson Reuters issued this assertion:
“We’re dedicated to analysis and fostering relationships with trade companions that furthers the event of protected and trusted AI. Thomson Reuters believes that any analysis which incorporates its options ought to be accomplished utilizing the product for its meant function, and as well as that any benchmarks and definitions are established in partnership with these working within the trade.
“On this research, Stanford used Sensible Legislation’s Ask Sensible Legislation AI for major regulation authorized analysis, which isn’t its meant use, and would understandably not carry out properly on this atmosphere. Westlaw’s AI-Assisted Analysis is the appropriate software for this work.”
Defining Hallucination
Within the research, the LexisNexis AI authorized analysis software carried out extra favorably than the Thomson Reuters software. However, as I’ve already made clear, that is in no way a good comparability, as a result of the research didn’t make use of the Thomson Reuters product that’s akin to the LexisNexis product.
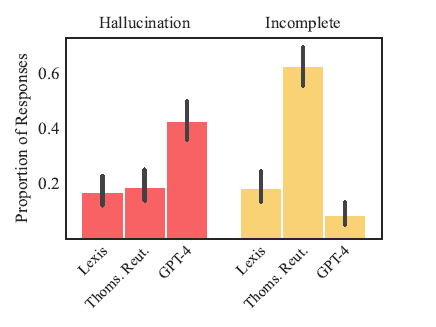
As this graph from the research exhibits, LN and TR have been kind of equal within the numbers of hallucinated solutions they offered. Nevertheless, TR’s product delivered a a lot increased variety of incomplete solutions.
What does it imply that a solution is hallucinated? The research defines it this fashion:
“A response is taken into account hallucinated whether it is both incorrect or misgrounded. In different phrases, if a mannequin makes a false assertion or falsely asserts {that a} supply helps a press release, that constitutes a hallucination.”
This can be a broader definition than some could use when talking of hallucinations, as a result of it encompasses not simply fabricated sources, but in addition sources which might be irrelevant to the question or that contradict the AI software’s claims.
For instance, in the identical chart above that contained the Obergefell instance, the Lexis reply relating to the usual of evaluate for abortion instances included a quotation to an actual case that has not been overturned. Nevertheless, that actual case contained a dialogue of a case that has been overruled, and the AI drew its reply from that dialogue.
“In truth, these errors are doubtlessly extra harmful than fabricating a case outright, as a result of they’re subtler and harder to identify,” the research’s authors say.
Along with measuring hallucinated responses, the research additionally tracked what it thought-about to be incomplete responses. These have been both refusals to reply a question or solutions that, whereas not essentially incorrect, failed to offer supporting authorities or different key info.
In opposition to these requirements, LexisNexis got here out higher within the research:
“General hallucination charges are comparable between Lexis+ AI and Thomson Reuters’s Ask Sensible Legislation AI, however these top-line outcomes obscure dramatic variations in responsiveness. … Lexis+ AI supplies correct (i.e., appropriate and grounded) responses on 65% of queries, whereas Ask Sensible Legislation AI refuses to reply queries 62% of the time and responds precisely simply 18% of the time. When wanting solely at responsive solutions, Thomson Reuters’s system hallucinates at an analogous fee to GPT-4, and greater than twice as usually as Lexis+ AI.”
LexisNexis Responds
Jeffrey S. Pfeifer, chief product officer for LexisNexis Authorized and Skilled, informed me that the research’s authors by no means contact LN whereas performing their research and that LN’s personal evaluation indicated a a lot decrease fee of hallucination. “It seems the research authors have taken a wider place on what constitutes a hallucination and we worth the framework urged by the authors,” he stated.
“Lexis+ AI delivers hallucination-free linked authorized citations,” Pfeifer stated. “The emphasis of ‘linked’ signifies that the reference will be reviewed by a person by way of a hyperlink. Within the uncommon occasion {that a} quotation seems with no hyperlink, it is a sign that we can’t validate the quotation in opposition to our trusted information set. That is clearly famous throughout the product for person consciousness and clients can simply present suggestions to our improvement groups to assist steady product enchancment.
With regard to LN’s use of RAG, Pfeifer stated that responses to queries in Lexis+ AI “are grounded in an in depth repository of present, unique authorized content material which ensures the highest-quality reply with probably the most up-to-date validated quotation references.”
“This research and different latest feedback appear to misconceive the usage of RAG platforms within the authorized trade. RAG infrastructure shouldn’t be merely search related to a big language mannequin. Neither is RAG the one know-how utilized by LexisNexis to enhance authorized reply high quality from a big language mannequin. Our proprietary Generative AI platform contains a number of providers to infer person intent, body content material recall requests, validate citations by way of the Shepard’s quotation service and different content material rating – all to enhance reply high quality and mitigate hallucination threat.”
Pfeifer stated that LN is frequently working to enhance its product with a whole lot of hundreds of rated reply samples by LexisNexis authorized subject material consultants used for mannequin tuning. He stated that LN employs greater than 2,000 technologists, information scientists, and J.D. subject material consultants to develop, take a look at, and validate its merchandise.
He famous (as do the authors of the research) that the research was carried out earlier than LN launched the newest model of its Lexis+ AI platform.
“The Lexis+ AI RAG 2.0 platform was launched in late April and the service enhancements handle most of the points famous,” Pfeifer stated. “The exams run by the Stanford group have been prior to those latest upgrades and we might count on even higher efficiency with the brand new RAG enhancements we launch. The know-how accessible in supply content material recall is bettering at an astonishing fee and customers will see week over week enhancements within the coming months.”
Pfeifer goes on to say:
“As famous, LexisNexis makes use of many strategies to enhance the standard of our responses. These embody the incorporation of proprietary metadata, use of information graph and quotation community know-how and our world entity and taxonomy providers; all help in surfacing probably the most related authority to the person. The research appears to recommend that RAG deployments are usually interchangeable. We’d disagree with that conclusion and the LexisNexis reply high quality benefits famous by the research are the results of enhancements we’ve got deployed and proceed to deploy in our RAG infrastructure.
“Lastly, LexisNexis can be centered on bettering intent recognition of person prompts, which fits alongside figuring out the simplest content material and providers to handle the person’s immediate. We proceed to coach customers on methods to immediate the system extra successfully to obtain the absolute best outcomes with out requiring deep prompting experience and expertise.
“Our purpose is to offer the best high quality solutions to our clients, together with hyperlinks to validated, high-quality content material sources. The Stanford research, in reality, notes persistently increased efficiency from Lexis+ AI as in comparison with open supply generative AI options and Ask PLC from Thomson Reuters.”
Backside Line
Despite the fact that the research finds that these authorized analysis merchandise haven’t eradicated hallucinations, it however concludes that “these merchandise can supply appreciable worth to authorized researchers in comparison with conventional key phrase search strategies or general-purpose AI methods, notably when used as step one of authorized analysis fairly than the final phrase.”
However noting that attorneys have an moral duty to grasp the dangers and advantages of know-how, the research’s authors conclude with a name for better transparency into the “black field” of AI merchandise designed for authorized professionals.
“An important implication of our outcomes is the necessity for rigorous, clear benchmarking and public evaluations of AI instruments in regulation. … [L]egal AI instruments present no systematic entry, publish few particulars about fashions, and report no benchmarking outcomes in any respect. This stands in marked distinction to the overall AI subject, and makes accountable integration, supervision, and oversight acutely troublesome.
“Till progress on these fronts is made, claims of hallucination-free authorized AI methods are, at greatest, ungrounded.”